zfn9
zfn9
In today’s data-driven world, managing large amounts of information can quickly become overwhelming. The The Pandas Python library offers a powerful solution for data management and analysis. Whether you’re a data scientist, researcher, or business analyst, Pandas streamlines tasks such as cleaning, transforming, and analyzing data, turning complex workflows into seamless processes.
Pandas provides an easy-to-use interface and robust capabilities, making it an essential tool for anyone dealing with structured data. Let’s explore how Pandas can make data handling smoother and simplify complex tasks.
Getting Started with Pandas: Installation Guide
install pandas ```
## Understanding Pandas and Its Core Features
Pandas is an open-source Python library designed for data manipulation and
analysis. Built on top of NumPy, it offers powerful data structures like
Series and DataFrame, allowing users to store and manipulate data efficiently.
Unlike traditional spreadsheet tools, Pandas performs high-efficiency
operations on large datasets. The key advantage of Pandas is its intuitive
processing of structured data, crucial for managing large data volumes.
The most basic data structure in Pandas is the Series, a one-dimensional array
akin to a spreadsheet column. A Series includes values and associated labels,
simplifying access to specific elements. The second fundamental structure is
the DataFrame, a two-dimensional table capable of storing and manipulating
heterogeneous data types, similar to an Excel worksheet. DataFrames support
sorting, filtering, grouping, and merging operations, making them invaluable
for managing complex datasets.
Pandas also efficiently handles missing data, a common issue in real datasets.
It offers built-in functionality to identify, fill in, or drop missing values
with minimal manual intervention. Additionally, Pandas integrates seamlessly
with other Python packages, including Matplotlib and Seaborn for plotting,
NumPy for numeric computation, and SQL databases for structured queries.
Key features include:
* Data alignment and missing data handling
* Flexible reshaping and pivoting
* Time series functionality
* Integration with SQL databases and file formats (CSV, Excel, JSON)
```python import pandas as pd # Create a DataFrame from a dictionary data = {
'Product': ['Laptop', 'Phone', 'Tablet'], 'Price': [999.99, 699.99, 299.99],
'Units Sold': [150, 300, 200] } df = pd.DataFrame(data) print(df) ```
## Why Pandas Is Essential for Data Handling?
Efficient data handling is crucial across various industries, making Pandas
indispensable for data manipulation and analysis. In data science,
professionals work with large volumes of data that require cleaning and
transformation before insights can be drawn. Pandas simplifies these tasks
with easy-to-use built-in functions for reshaping, aggregating, and analyzing
datasets.

In business, marketing teams rely on customer data to drive strategic
decisions. Pandas allows them to filter transactions, identify trends, and
visualize patterns, streamlining the process of extracting actionable
insights. In finance, Pandas is essential for managing stock market data,
analyzing performance, and calculating key risk metrics. Researchers and
scientists also use Pandas to efficiently process experimental data, making it
a comprehensive tool for data professionals across various fields.
Pandas' efficiency is a standout feature. Unlike traditional spreadsheet
applications that struggle with large datasets, Pandas operates effectively
with millions of rows of data. This capability enables users to tackle real-
world problems without memory issues or slowdowns. Additionally, Pandas can
read and write multiple file formats like CSV, Excel, JSON, and SQL, ensuring
seamless data handling across different platforms and use cases.
Example: Filtering 1 million rows takes milliseconds in Pandas vs. minutes in
spreadsheets.
```python # Filter products with sales > 200 units high_sales = df[df['Units
Sold'] > 200] print(high_sales) ```
## How Pandas Transforms Data Analysis?
Pandas is a powerful tool that streamlines various stages of data analysis,
including data collection, cleaning, transformation, and visualization. One of
its key features is data filtering, allowing users to extract relevant subsets
from large datasets effortlessly. Analysts can quickly sort through vast
amounts of data using simple commands, simplifying the search for specific
information.
Another valuable feature is data grouping and aggregation. Pandas’ `groupby()`
function simplifies the process of summarizing and comparing data segments,
such as analyzing revenue by region or customer demographics. Additionally,
its data merging and joining capabilities allow users to combine multiple
datasets seamlessly, saving time and reducing complexity.
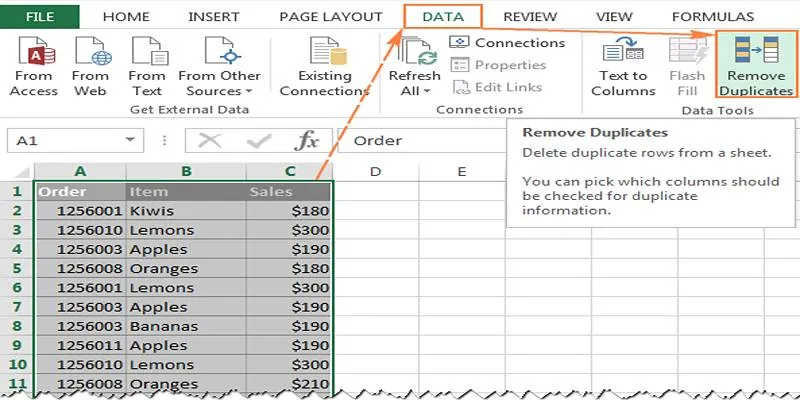
Data transformation is a key strength of Pandas. Raw data often contains
inconsistencies or duplicates. With functions like `fillna()` for handling
missing values and `drop_duplicates()` for removing redundant entries, Pandas
ensures data accuracy and reliability.
Pandas also integrates well with visualization tools like Matplotlib and
Seaborn, enabling users to generate detailed charts and graphs that uncover
trends and correlations.
Moreover, Pandas plays a significant role in machine learning by preparing
datasets for training models, handling tasks like encoding categorical data,
normalizing values, dealing with outliers, and ensuring proper data
structuring before applying machine learning techniques.
## The Future of Pandas in Data Science
As the demand for data-driven decision-making increases, Pandas continues to
evolve to meet new challenges. The library is frequently updated with
performance enhancements to maintain its efficiency with large-scale datasets.
With the rise of big data, cloud computing, and artificial intelligence,
Pandas is being optimized to handle more complex tasks.

One major advancement is improved support for real-time data streams, enabling
businesses in sectors like finance, IoT, and social media to analyze live data
seamlessly. Additionally, Pandas is integrating with distributed computing
frameworks like Dask and Apache Spark, allowing users to scale operations
across multiple machines.
Another exciting development is Pandas' integration with cloud-based analytics
platforms, facilitating the manipulation and analysis of cloud-stored data. As
Pandas' popularity grows, education and training in Pandas are becoming more
accessible, with many online resources and company training programs available
to help professionals develop critical data skills for decision-making.
## Conclusion
Pandas is an indispensable library for anyone working with Python data. It
simplifies tasks like managing, cleaning, transforming, and analyzing data,
making it essential across various industries. With its seamless integration
with other Python tools, it's a must-have for handling structured data. As
technology evolves, Pandas continues to adapt, especially in big data, machine
learning, and cloud computing. Learning Pandas opens up valuable
opportunities, ensuring its place as a cornerstone in Python’s data ecosystem
for years ahead.