zfn9
zfn9
Python has emerged as a leading programming language, primarily due to its extensive ecosystem of libraries. Among these, Pandas stands out as an essential tool for data analysis. Pandas simplifies the management of spreadsheets, databases, and raw data by offering intuitive structures like DataFrames and Series for efficient manipulation. It streamlines tasks like filtering, transforming, and performing statistical computations, reducing the need for repetitive coding.
Ideal for both beginners and professionals, Pandas enables the smooth processing of large datasets. Its flexibility and power make it indispensable for tasks ranging from simple data transformations to cutting-edge analytics, cementing its status as a fundamental tool for anyone working with data in Python.
What is Pandas?
Pandas is an open-source Python library designed for data manipulation and analysis. It provides data structures, primarily Series and DataFrame, which allow users to store, access, and process data efficiently. Built to work seamlessly with other scientific computing libraries like NumPy and Matplotlib, Pandas enables data scientists and analysts to handle large datasets effortlessly.
Created by Wes McKinney in 2008 to offer financial analysts a simple data manipulation tool, Pandas has evolved into one of Python’s most popular libraries. It plays a vital role in data science, machine learning, and programming. Pandas is particularly valued for its ability to handle structured data, making it widely used in fields such as finance, research, medicine, and artificial intelligence.
Pandas optimizes processes that would otherwise require extensive manual coding. With just a few lines of code, users can clean, transform, and analyze datasets, making it an indispensable tool for any Python programmer dealing with data. Its intuitive syntax and robust functions make it a top choice for processing datasets of all sizes, from small collections to large data platforms.
How Does Pandas Work?
At its core, Pandas revolves around two principal data structures: the Series and the DataFrame.

A Series is a one-dimensional array-like structure that holds data of any type, such as numbers, strings, or even Python objects. It resembles a column in a spreadsheet or a single Python list and is convenient for handling individual data points or time series data.
A DataFrame, by contrast, is a two-dimensional structure that resembles a table with rows and columns. This is the most commonly used data structure in Pandas, as it facilitates the organization of large amounts of data in a structured format. A DataFrame can be created from multiple data sources, including CSV files, Excel spreadsheets, SQL databases, or even dictionaries and lists.
One of Pandas’ most powerful features is its ability to handle missing data seamlessly. Unlike traditional programming techniques that require extensive condition-based logic to manage incomplete data, Pandas offers built-in functions to fill, replace, or drop missing values. This ensures data integrity and saves time when preparing datasets for analysis.
Additionally, Pandas makes data manipulation incredibly easy. Users can filter, sort, and group data using straightforward syntax, simplifying tasks such as:
- Selecting specific columns or rows
- Applying mathematical operations across datasets
- Aggregating data based on custom conditions
Pandas also integrates well with visualization libraries like Matplotlib and Seaborn, enabling users to generate charts and graphs directly from their DataFrames. This makes it an excellent tool for exploratory data analysis, where patterns and trends can be quickly identified.
Key Features of Pandas
Pandas is packed with features that make data manipulation straightforward and efficient. Some key features include:
Flexible Data Structures: With Series and DataFrames, Pandas supports various data formats, allowing seamless manipulation, transformation, and analysis across different applications.
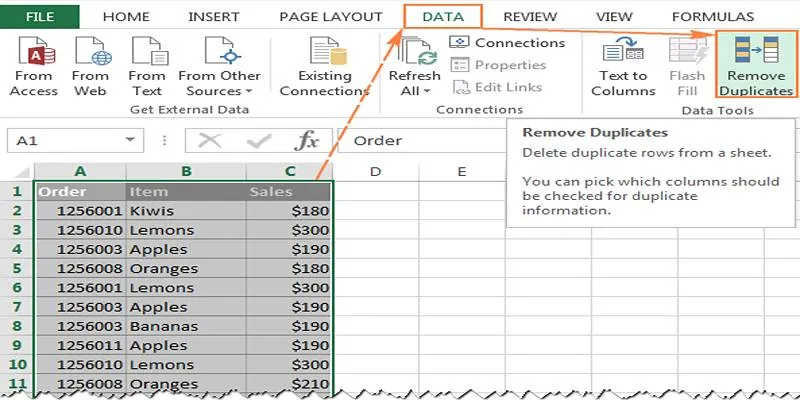
Data Cleaning and Preparation: Pandas simplifies handling missing values, duplicates, and inconsistent data, ensuring structured, accurate, and high- quality datasets for analysis.
Seamless Integration: Pandas works with NumPy for numerical computations and Matplotlib for visualizations, enhancing data analysis workflows across different domains.
Easy Data Import and Export: Pandas effortlessly loads and saves data in multiple formats, including CSV, Excel, JSON, and SQL, streamlining data exchange between various platforms.
Why Pandas is Essential for Data Analysis?
Pandas has become a fundamental tool for data analysis because it efficiently handles data. Traditional methods of data manipulation, such as working with lists and dictionaries in Python, can be cumbersome and inefficient. Pandas streamlines this process, making data processing faster and more reliable.

One of Pandas’ biggest advantages is its capability to process large datasets with ease. Unlike Excel, which struggles with large amounts of data, Pandas can handle millions of rows without performance issues. This makes it an ideal choice for industries dealing with massive datasets, such as finance, healthcare, and e-commerce.
Pandas also simplifies data cleaning, a crucial step in data analysis. Datasets are rarely perfect, often containing missing values, duplicates, or inconsistencies. Pandas provides powerful functions to clean and prepare data, ensuring analysts work with accurate and well-structured information.
Another reason for Pandas’ widespread adoption is its compatibility with machine learning and artificial intelligence workflows. Most machine learning models require structured data as input, and Pandas makes it easy to prepare and format data accordingly. It integrates well with popular libraries such as Scikit-learn, TensorFlow, and PyTorch, making it an essential tool in the machine-learning pipeline.
Beyond analysis, Pandas enables users to export their processed data in various formats. Whether saving data as a CSV file, writing it to a database, or converting it into JSON format, Pandas provides simple commands to ensure data is stored and shared efficiently.
Conclusion
Pandas in Python is an indispensable tool for data analysis, simplifying data manipulation with its powerful yet user-friendly structures. Its ability to handle large datasets, clean data efficiently, and integrate with other libraries makes it essential for analysts, developers, and researchers. Whether performing simple transformations or complex statistical operations, Pandas streamlines workflows and enhances productivity. As data-driven decision-making becomes increasingly vital, mastering Pandas equips users with the skills to manage, process, and analyze data effortlessly in Python.