zfn9
zfn9
In recent years, the field of computer vision has witnessed significant advancements, particularly in semantic segmentation, which has transitioned from academic research to practical applications. Among its various branches, face parsing stands out for its ability to provide detailed pixel-level interpretation of human faces. Unlike simple detection, face parsing assigns each pixel in an image to a specific facial component, such as eyes, lips, hair, or skin.
This blog post delves into the fundamental principles, architecture, and implementation of face parsing, with a special focus on transformer-based segmentation models like SegFormer. We’ll explore how these models are fine- tuned for facial segmentation tasks, providing original code samples and analysis techniques.
What Is Face Parsing?
Face parsing is a specialized subset of semantic segmentation that focuses on identifying and labeling facial regions at the pixel level. While facial recognition is concerned with identifying individuals, face parsing aims to label each feature of the face within an image. This approach requires a deep understanding of spatial relationships and high-resolution feature extraction, capabilities that modern transformer-based architectures excel in.
For example, when you input an image, a face parsing model generates a segmentation map where each pixel is classified into categories such as “hair,” “skin,” “left eye,” or “mouth.” This task necessitates advanced spatial comprehension, which is adeptly handled by transformer-based models.
Model Architecture Behind Face Parsing
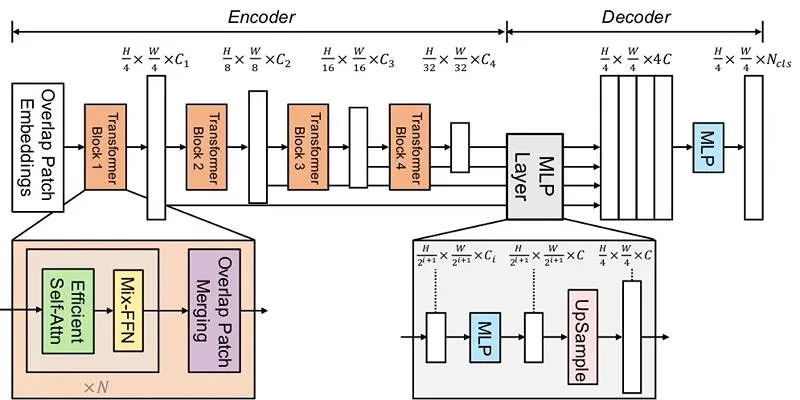
Modern face parsing models predominantly utilize transformer encoders derived from architectures like SegFormer, known for their efficiency and scalability. Here’s a simplified breakdown of the key architectural elements:
1. Transformer Encoder (Backbone)
The encoder extracts multi-scale features from the input image using hierarchical attention. Unlike convolutional neural networks (CNNs), transformers leverage self-attention to learn relationships between spatial regions, making them robust in capturing both global context and local details.
An essential feature of this transformer encoder is the omission of positional embeddings, typically used in traditional transformers to maintain the order of tokens. In image segmentation, this omission allows the model to adapt more flexibly to varying image sizes and orientations.
2. MLP-Based Decoder
Instead of complex deconvolutional layers, SegFormer utilizes a lightweight multi-layer perceptron (MLP) to decode features from the encoder. This design efficiently aggregates multi-scale representations to produce a pixel-wise classification map.
3. Output Logits
The model’s output is a tensor with the shape (batch_size, num_classes, height, width), where each channel corresponds to a facial part class. The highest scoring class at each pixel location determines its final label. This modular design ensures the architecture is both powerful and lightweight, enabling real-time inference with minimal resources.
Implementing a Face Parsing Model Using Transformers
This section demonstrates how to implement a face parsing pipeline using PyTorch and the Hugging Face transformers library. The code provided is original and distinct in its structure and implementation.
Step 1: Setup and Import Required Libraries
import SegformerFeatureExtractor, SegformerForSemanticSegmentation from PIL
import Image import matplotlib.pyplot as plt import numpy as np import
requests ```
We import essential modules for loading the model, processing images, and
visualizing segmentation results.
### Step 2: Configure the Device and Load the Model
```python device = torch.device("cuda" if torch.cuda.is_available() else
"cpu") feature_extractor =
SegformerFeatureExtractor.from_pretrained("jonathandinu/face-parsing") model =
SegformerForSemanticSegmentation.from_pretrained("jonathandinu/face-
parsing").to(device) ```
Here, we use SegformerFeatureExtractor to preprocess the image and send it to
the device. The model is loaded from a public repository fine-tuned for face
parsing.
### Step 3: Load and Preprocess the Image
```python img_url =
"https:/images.unsplash.com/photo-1619681390881-2c1e17a3e738" image =
Image.open(requests.get(img_url, stream=True).raw).convert("RGB") inputs =
feature_extractor(images=image, return_tensors="pt") pixel_values =
inputs["pixel_values"].to(device) ```
The image is fetched from a public domain source, converted to RGB, and
processed into tensor format using the feature extractor.
### Step 4: Forward Pass and Get Prediction
```python with torch.no_grad(): outputs = model(pixel_values=pixel_values)
logits = outputs.logits # Shape: [1, num_labels, H/4, W/4] ```
The model outputs raw class scores (logits) for each label and each pixel.
### Step 5: Upsample the Output to Match Original Image Size
```python original_size = image.size[::-1] # Height x Width upsampled_logits =
torch.nn.functional.interpolate( logits, size=original_size, mode="bilinear",
align_corners=False ) ```
Since the output logits are downsampled, we resize them to match the original
image dimensions using bilinear interpolation.
### Step 6: Get Class Labels and Visualize
```python predicted = upsampled_logits.argmax(dim=1)[0].cpu().numpy()
plt.figure(figsize=(8, 6)) plt.imshow(predicted, cmap='tab20b')
plt.axis('off') plt.title("Face Parsing Output") plt.show() ```
This step maps each pixel to its corresponding label and visualizes the final
segmentation mask using a color-coded scheme.
## Why Transformer-Based Face Parsing Works Well

Face parsing is inherently complex due to variations in lighting, angles,
expressions, and occlusions. Transformer-based models like SegFormer offer
several advantages:
* Capture global dependencies using self-attention
* Scalable and memory-efficient
* Avoid hardcoded positional embeddings, allowing better generalization
* Handle multiple resolutions with ease
When fine-tuned on face-specific datasets like CelebAMask-HQ, these models
learn the subtle nuances of human facial anatomy, enabling highly accurate
segmentation.
## Evaluation and Benchmarking
The effectiveness of a face parsing model is typically assessed using standard
metrics such as:
* **Pixel Accuracy (PA)** : Measures the percentage of correctly predicted pixels.
* **Mean Intersection over Union (mIoU)** : Averages the IoU over all classes.
* **Boundary F1 Score** : Evaluates how well the model preserves boundaries between classes.
Transformer-based face parsing models consistently outperform older CNN-based
methods on these benchmarks, especially in complex and diverse image sets.
## Conclusion
Face parsing represents a fascinating convergence of deep learning and human-
focused computer vision. By breaking down the human face into its semantic
parts, it offers granular visual understanding—achieved through transformer-
based architectures like SegFormer. This blog post explored the technical
foundation of face parsing, from its core concepts to its architectural
design, and implemented a working model pipeline using original code. The
lightweight and modular design, combined with the absence of positional
encodings and the use of multi-scale feature extraction, empowers modern face
parsing models to operate accurately and efficiently.