zfn9
zfn9
In the realm of machine learning and AI, achieving optimal model performance is crucial. Two common issues affecting this performance are overfitting and underfitting. Overfitting occurs when a model becomes overly complex and fits the training data too closely, while underfitting happens when the model is too simplistic and fails to capture the patterns in the data. Striking a balance between these extremes is essential for developing AI models that generalize well and make accurate predictions on new data.
Understanding Overfitting
Overfitting takes place when a model becomes excessively complex, effectively “memorizing” the training data rather than learning to generalize for unseen data. This means the model performs exceptionally well on the training data but struggles to make accurate predictions on new data.
Key Indicators of Overfitting:
- High accuracy on the training set
- Poor performance on validation or test data
- An overly detailed model capturing noise instead of underlying trends
Overfitting is similar to memorizing answers to specific questions rather than understanding the broader concept. It often arises when a model has too many parameters or is trained excessively on limited data.
Understanding Underfitting
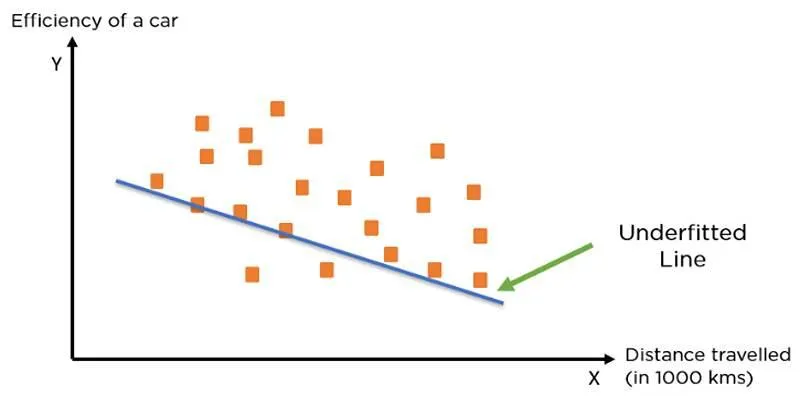
Underfitting occurs when a model is too simplistic to detect the patterns in the data, resulting in poor performance on both the training set and unseen data. This may indicate that the model lacks the complexity needed to learn the underlying relationships, leading to inaccurate predictions.
Key Indicators of Underfitting:
- Low accuracy on both training and test sets
- An overly simplistic model unable to grasp complex patterns
- Use of too few parameters or overly simplified models
Underfitting is akin to attempting to answer questions without understanding the core material, rendering the model unable to predict even the simplest outcomes accurately.
Impact of Overfitting and Underfitting on AI Model Performance
Both overfitting and underfitting adversely affect machine learning models , albeit in different ways. While overfitting results in a model tailored too closely to training data, underfitting leads to a model that fails to learn sufficiently from the data. A well-balanced model should generalize effectively to unseen data, maintaining a balance between complexity and simplicity. Without this balance, the model’s predictions will be inaccurate and unreliable.
Effects of Overfitting on AI Models:
- Reduced model generalization
- Increased error rate on new, unseen data
Effects of Underfitting on AI Models:
- Poor performance across all datasets
- Lack of complexity in predictions
Strategies to Prevent Overfitting
Data scientists employ various strategies to mitigate overfitting. These techniques aim to simplify the model while still capturing essential data patterns.
Regularization:
Regularization methods like L1 and L2 penalties introduce a cost for larger model parameters, encouraging the model to remain simple and avoid fitting noise.
Cross-Validation:
Cross-validation involves dividing the data into multiple parts and training the model on different subsets. This approach allows for a more accurate assessment of the model’s ability to generalize to new data.
Pruning:
In decision trees, pruning removes unnecessary branches that contribute little to the model’s predictive power, effectively simplifying the model.
Strategies to Prevent Underfitting
While overfitting necessitates reducing complexity , underfitting requires enhancing the model’s learning capability. Here are a few techniques to avoid underfitting:
Increase Model Complexity:
If a model is underfitting, it may be too simple to capture data relationships. Adding more parameters or using a more complex algorithm can enhance the model’s learning ability.
Extended Training Time:
Sometimes, a model needs additional training to understand underlying patterns. Allowing the model to train longer can prevent underfitting, especially in deep learning models.
The Role of Data in Overfitting and Underfitting
Data quality and quantity significantly impact both overfitting and underfitting. Insufficient data can cause underfitting, while excessive data that is not representative can lead to overfitting.
Data Quality:
High-quality data, with minimal noise and outliers, helps prevent overfitting by allowing the model to focus on essential patterns. It also prevents underfitting by providing enough variability for effective learning.
Data Quantity:
A larger volume of data can prevent overfitting by enabling the model to generalize across diverse scenarios. Conversely, too little data may lead to underfitting due to insufficient variation for the model to learn from.
Evaluating Model Performance: Balancing Overfitting and Underfitting

After training a model, it is crucial to evaluate its performance to check for overfitting or underfitting. This can be done using various metrics and techniques, including:
Accuracy:
Accuracy measures the proportion of correctly predicted outcomes. However, relying solely on accuracy can be misleading if the model is overfitting or underfitting, so additional metrics are often considered.
Precision and Recall:
Precision measures the correctness of positive predictions, while recall assesses the model’s ability to identify all positive instances. These metrics offer a more comprehensive evaluation of model performance than accuracy alone.
F1 Score:
The F1 score combines precision and recall into a single metric, providing a more balanced assessment of a model’s predictive power.
Conclusion
Overfitting and underfitting are common challenges in building AI models. However, with appropriate techniques and a balanced approach, it’s possible to develop models that perform well on both training and unseen data. By carefully managing model complexity, ensuring data quality, and applying strategies like regularization and cross-validation, AI practitioners can build models that generalize effectively, delivering reliable predictions.