zfn9
zfn9
In unsupervised learning, the computer identifies patterns within data without predefined labels or outcomes. Unlike supervised learning, which uses both data and labels for model training, unsupervised learning explores patterns or structures inherent in the data. This method is crucial for data analysis, especially when labeled data is scarce or unavailable. This post will discuss the concept of unsupervised learning , its primary types, common applications, and real-world examples.
What is Unsupervised Learning?
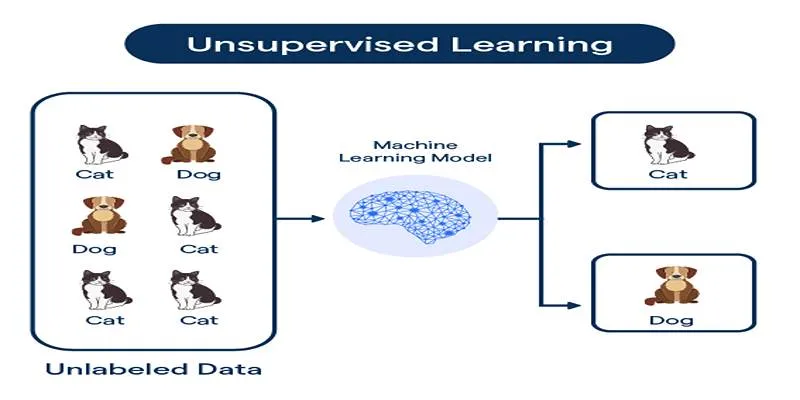
Unsupervised learning involves training a machine learning model on unlabeled data. The primary aim is for the algorithm to discover patterns, structures, or relationships within the data autonomously. It is pivotal in tasks such as clustering, anomaly detection, and dimensionality reduction, which are essential in data analysis scenarios where manual labeling is impractical or costly.
Types of Unsupervised Learning
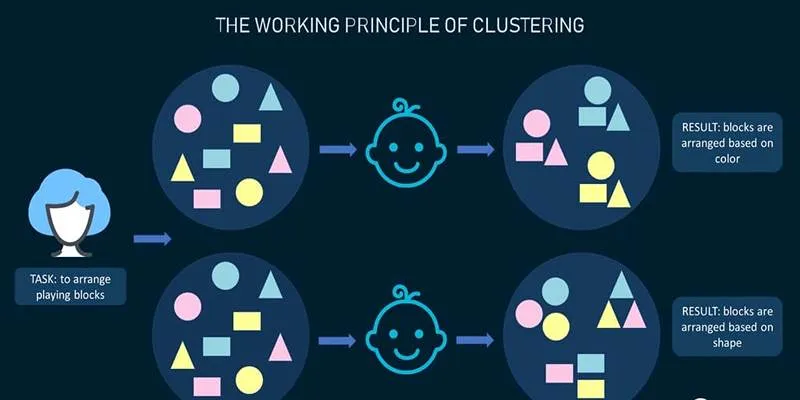
There are two main types of unsupervised learning : clustering and association. Both aim to analyze and reveal patterns within data, albeit with different objectives.
Clustering : Clustering involves grouping data points based on similarities. The algorithm naturally identifies which data points are most similar and groups them accordingly. This technique is commonly used in market segmentation, where customers are grouped based on purchasing behavior or preferences. Clustering can also categorize items such as images, documents, or geographical locations. K-Means is a prevalent clustering algorithm that assigns data points to clusters by minimizing the distance between the data points and the cluster centers.
Association : Association focuses on discovering relationships between variables within large datasets. For example, it can identify patterns like “customers who bought X also bought Y.” This technique is widely used in retail and e-commerce for product recommendations. Association is typically applied in recommendation systems, aiming to predict items based on a customer’s previous behavior. Supermarkets, for instance, use association rules to analyze purchasing habits, such as identifying that customers who buy milk often also buy bread, which can inform product suggestions or store layout optimization.
Common Algorithms in Unsupervised Learning
Several algorithms are commonly used in unsupervised learning tasks, each tailored to handle specific data types. Popular algorithms include:
- K-Means Clustering : Groups data into a specified number of clusters based on similarity.
- Hierarchical Clustering : Creates a tree-like structure to represent data clusters at various levels.
- Principal Component Analysis (PCA) : Used for dimensionality reduction by focusing on the most significant features, simplifying large datasets for analysis.
- DBSCAN : A density-based algorithm that groups closely located points and identifies outliers as noise.
These algorithms can be adapted to various data types and application areas, depending on the problem at hand.
Applications of Unsupervised Learning
Unsupervised learning has numerous practical applications across various industries. It plays a crucial role in enabling organizations and researchers to derive valuable insights from large, unlabeled datasets. Key applications include:
Customer Segmentation : Companies utilize unsupervised learning to segment customers into groups with similar characteristics, such as buying behavior or demographic information, enhancing targeted marketing efforts.
Anomaly Detection : In cybersecurity or fraud detection, unsupervised learning identifies unusual patterns that may indicate security breaches or fraudulent activity, such as detecting atypical credit card transactions to prevent fraud.
Recommender Systems : Many online platforms employ unsupervised learning to recommend products or content based on users’ previous behaviors, like Netflix suggesting movies or Amazon recommending products.
Challenges in Unsupervised Learning
While unsupervised learning is powerful, it poses several challenges. One significant difficulty is the lack of predefined outputs, complicating model performance evaluation. Unlike supervised learning, where predictions can be compared to known labels, unsupervised learning requires different evaluation methods, such as clustering validity indices or domain-specific metrics.
Moreover, unsupervised learning algorithms can produce results that are challenging to interpret, especially with complex data. Sometimes, the algorithms may detect patterns that lack meaningful significance, necessitating careful expert analysis and validation.
Real-World Examples of Unsupervised Learning
Here are some real-world examples where unsupervised learning is actively applied:
Social Media Analytics : Social media platforms use unsupervised learning to analyze posts, comments, and interactions, identifying topics of interest, sentiments, or emerging trends. These insights assist businesses and organizations in understanding public opinion or customer behavior. For instance, Twitter employs unsupervised learning techniques to identify popular hashtags or emerging topics in real-time.
Healthcare Data : In healthcare, unsupervised learning identifies patterns in patient data, such as clustering patients with similar symptoms or discovering new subtypes of diseases. This has significant implications for personalized medicine and improving patient care.
Document Clustering : Unsupervised learning is also used to group documents or articles into categories. News agencies or content aggregators, for instance, employ clustering to group similar articles together, enhancing content recommendation engines and helping readers quickly find relevant articles.
Conclusion
Unsupervised learning is a critical technique in machine learning, enabling the extraction of valuable patterns and structures from unlabeled data. Despite challenges in evaluation and interpretation, its capacity to uncover hidden insights makes it a powerful tool for various applications, from customer segmentation to anomaly detection and beyond. As data continues to grow exponentially, the role of unsupervised learning will become increasingly significant in assisting businesses and researchers in deciphering complex datasets.