zfn9
zfn9
In the world of computer vision, things are moving fast—too fast for the old tools to keep up. For years, convolutional neural networks (CNNs) dominated the field, powering applications from facial recognition to self-driving cars. But a shift began when the Transformer architecture, originally designed for natural language processing, showed promise beyond text.
Then came Swin Transformers, an evolution that rewrote the rules of visual processing. Built to scale, flexible enough for diverse tasks, and efficient at handling image data in chunks rather than all at once, they now sit at the heart of modern computer vision innovation.
The Rise of Swin Transformers in Visual Tasks
Swin Transformers, short for Shifted Window Transformers, were introduced as a solution to one major challenge—how to apply the success of Transformers in NLP to vision without being crushed by computational costs. Unlike vanilla Vision Transformers (ViTs), which treat images as flat sequences and process them globally, Swin Transformers process visual data hierarchically, just like CNNs. This approach provides the best of both worlds: the flexibility of Transformers and the efficiency of localized processing.
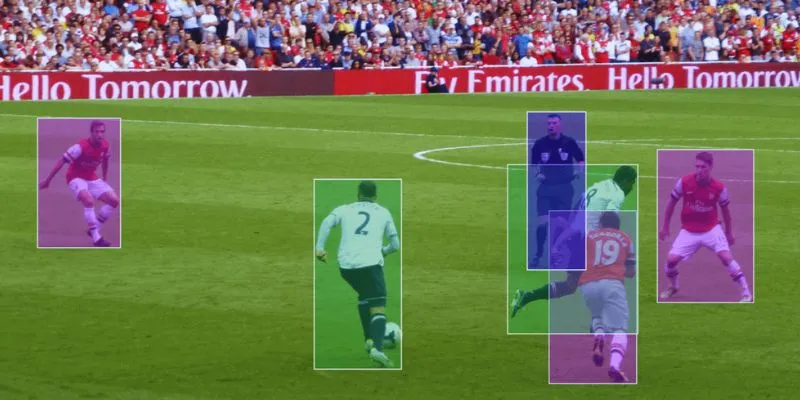
The key idea behind Swin Transformers is their use of non-overlapping windows to compute self-attention. These windows are then shifted at each layer, allowing information to gradually propagate across an entire image. This shift in design enables Swin Transformers to handle high-resolution images efficiently and apply themselves to dense prediction tasks, such as object detection and semantic segmentation—domains where earlier Transformers struggled.
At their core, Swin Transformers create a pyramid-like structure where features are aggregated at multiple scales. This allows them to represent both fine details and broad patterns, which is crucial for understanding complex visual scenes. In practice, this makes them highly adaptable for tasks like instance segmentation, pose estimation, and even video analysis, outperforming previous models that were tightly bound to either global attention or local convolution.
How Swin Transformers Differ from Conventional Architectures
Before Swin Transformers, convolutional networks dominated computer vision by efficiently capturing local patterns with low computational cost. But CNNs struggled with long-range dependencies—capturing broader context required stacking many layers, which made models heavier and still blind to global structure.

Then came Vision Transformers, offering global self-attention where every image patch could interact with every other. Powerful, yes—but also expensive. Their quadratic complexity with respect to image size made them impractical for high-resolution or real-time tasks.
Swin Transformers strike a balance. They process images in fixed-size windows and then shift those windows slightly at each layer. This lets the model see more of the image over time without needing global attention from the start. It’s like scanning a scene through overlapping frames—local context first, then gradually piecing together the global picture.
This approach keeps computation efficient while still boosting performance. On benchmarks like COCO for object detection and ADE20K for segmentation, Swin Transformers outperform older backbones like ResNet and EfficientNet. They’re also modular, slotting neatly into systems like Faster R-CNN and Mask R-CNN, often improving results without requiring a full pipeline redesign.
Real-World Applications and Task Performance
Swin Transformers have quickly become central to many high-impact tasks in computer vision. In object detection, where identifying and localizing multiple items is key, Swin’s hierarchical design helps preserve both fine detail and broader context. That balance makes them naturally suited for recognizing small and large objects alike, even in cluttered scenes.
For semantic segmentation, which requires classifying every pixel, Swin Transformers outperform traditional CNNs by learning spatial hierarchies directly from data. This means crisper object boundaries and better accuracy, especially in complex environments. Unlike CNNs, they don’t depend on handcrafted pooling or dilation tricks to see the bigger picture.
In image classification, Swin Transformers rival top-performing models on datasets like ImageNet-1K and 22K. They scale effectively while using fewer parameters than previous vision Transformers, making them both powerful and efficient. That performance also translates into video recognition, where they can analyze motion and object changes across frames without breaking the temporal flow—a major improvement over CNNs that treat each frame separately.
Finally, their architecture suits multi-modal tasks such as visual question answering and image captioning. Their shared Transformer backbone lets them combine visual and textual information naturally, making Swin Transformers an ideal choice for cross-modal AI systems.
The Future of Vision with Swin Transformers
Swin Transformers are not just another tool in the deep learning toolbox—they represent a structural evolution in how we approach visual understanding. They’ve proven that attention mechanisms can be local and efficient without sacrificing global context. They’ve also shown that you don’t need to choose between CNNs and Transformers—you can design systems that learn from both.

Future research is likely to push Swin Transformers even further into applications like robotics, where real-time processing and adaptability are crucial. Their compatibility with vision-language models also opens the door to richer AI systems that can interact with the world visually and verbally. Moreover, lightweight variants of Swin are already being explored to deploy on edge devices, bringing powerful visual intelligence to smartphones, wearables, and autonomous drones.
We can also expect to see continued refinement in training strategies, including better pretraining, more data-efficient learning, and perhaps tighter integration with unsupervised or self-supervised methods. All this will likely make Swin Transformers not just powerful but more accessible to smaller teams and research labs without giant compute budgets.
At its heart, the Swin Transformer is a signal that the architecture wars in computer vision may be over. Instead of choosing between CNNs and Transformers, the future lies in smart hybrids that borrow the best from both.
Conclusion
The rise of Swin Transformers marks a turning point in the evolution of computer vision. With their clever use of shifted windows, hierarchical modeling, and efficient computation, they’ve managed to bridge the gap between traditional CNNs and attention-based models. Their performance across a wide array of vision tasks—from image classification to object detection and beyond—proves that this architecture isn’t just a fleeting trend. It’s a new foundation. As the field continues to grow, tools like Swin will likely play a central role in shaping how machines see, interpret, and interact with the visual world around us.