zfn9
zfn9
Video recognition has traditionally required significant time and resources. As more mobile applications integrate video processing, the demand for real- time, lightweight solutions has skyrocketed. In this context, MoViNets, or mobile video networks, offer a robust and efficient alternative.
MoViNets are designed to balance accuracy, speed, and memory usage, enabling devices with limited resources to understand videos. This architecture allows for highly efficient video intelligence without the typical heavy computing load, applicable from action recognition to real-time analysis on mobile phones.
Let’s explore what makes MoViNets unique, how they function, and their place in the evolving world of AI-powered video recognition.
What Are MoViNets?
MoViNets, or Mobile Video Networks , are advanced deep learning models crafted for efficient video recognition on mobile and edge devices. Unlike traditional 3D convolutional networks that demand extensive memory and computing power, MoViNets are lightweight, fast, and optimized for real-time streaming.
The innovation of these models lies in their handling of temporal information. Video data is not merely a collection of images; it’s a sequence. MoViNets address this by processing video frames in a way that effectively captures spatial and temporal patterns, even on hardware-limited devices.
Core Innovations of MoViNets

The brilliance of MoViNets lies in their construction and functionality. Several techniques combine to enhance their efficiency:
Neural Architecture Search (NAS)
MoViNets are built on a search-based approach. Utilizing NAS, the architecture explores countless combinations of kernel sizes, filter numbers, and layer depths to pinpoint the optimal setup for a specific task. This method allows for automatic fine-tuning between performance and resource usage.
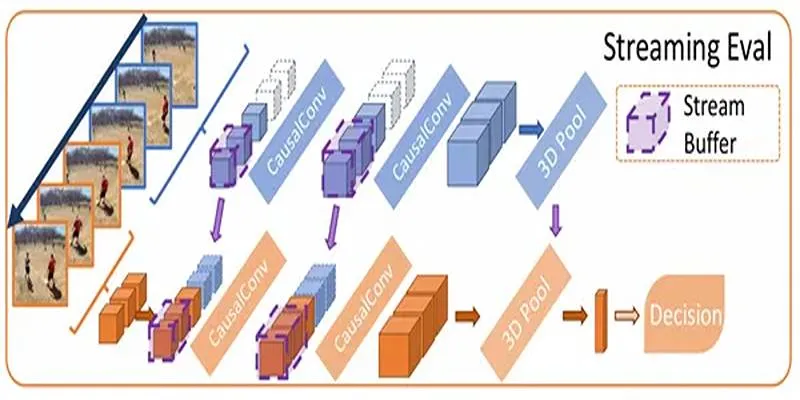
Stream Buffers
A significant challenge in video recognition is the memory required to process long sequences. MoViNets address this with stream buffers, dividing the video into smaller, manageable clips. Instead of reprocessing overlapping frames, stream buffers store features from clip ends, preserving long-term dependencies without excessive memory use.
Causal Operations
For real-time video analysis , models must process data as it arrives. MoViNets employ causal convolutions, where each output frame relies only on current and previous inputs. This is crucial for streaming applications like live video feeds.
Temporal Ensembling
To maintain accuracy while operating efficiently, MoViNets use temporal ensembling. Two identical models process the same video at staggered frame intervals, averaging their predictions for improved accuracy with minimal computational demand.
Advantages of MoViNets
MoViNets offer several key benefits:
- Efficient Memory Use : Their stream-based architecture significantly reduces memory demands, making them ideal for mobile or edge deployment.
- Real-Time Processing : Causal operations allow them to handle live video, frame by frame, without delay.
- Scalable Models : Various versions (A0 to A5) allow users to prioritize speed or accuracy.
- Competitive Accuracy : Despite their lightweight nature, they perform comparably to many large-scale video recognition models.
- Versatility : Suitable for applications ranging from security surveillance to fitness apps and smart home automation.
Why MoViNets Matter Today?
The demand for efficient video analysis is rapidly increasing. Whether it’s scene understanding in autonomous vehicles, patient monitoring in healthcare, or anomaly detection in live security footage, devices must intelligently handle video, often in real-time.
MoViNets bring high-performance action recognition and scene understanding to platforms where power and memory are scarce. They accomplish what was once thought impossible: efficient and accurate video processing on smartphones, embedded cameras, and IoT sensors.
Unlike heavy 3D CNN models, which require extensive computational resources, MoViNets offer a refreshing balance. They maintain accuracy without overloading hardware, a key factor in enabling edge AI at scale.
Where Can MoViNets Be Used?

Thanks to their efficiency and ability to operate on mobile and edge devices, MoViNets are ideal for real-time video recognition in various practical scenarios. These models can enhance both consumer-facing applications and critical infrastructure systems.
1. Smart Surveillance Systems
Deploy MoViNets on-site to detect suspicious activity in real-time without streaming everything to a central server.
2. Video Conferencing Tools
Enhance virtual meetings by detecting gestures, expressions, or background actions without straining device resources.
3. Health Monitoring Devices
Utilize in hospitals or wearables to monitor patients through video-based analysis of posture, movement, or facial expressions.
4. Augmented Reality (AR)
Mobile AR apps can leverage MoViNets to recognize motion patterns and objects within the user’s environment.
5. Sports Analytics
Analyze plays and player movements during a match to provide insights to coaches or fans in real-time.
How MoViNets Are Trained?
The training of MoViNets involves the Kinetics-600 dataset—a large-scale action recognition benchmark comprising 600 action categories from YouTube videos. This dataset offers a diverse set of human activities, making it ideal for training models intended for real-world video understanding tasks.
- Splitting Videos Into Short Clips
Instead of using full-length videos, the dataset is divided into smaller clips, typically a few seconds long. These shorter segments enable the model to capture fine-grained temporal patterns within manageable time windows, reducing memory usage during training and improving convergence rates.
- Applying Data Augmentation
Various transformations, like random cropping, horizontal flipping, brightness adjustments, and temporal jittering, are applied to each clip to improve generalization. These augmentation techniques help the model become robust to different video conditions, lighting, angles, and speeds.
- Using Causal Convolutions For Temporal Ordering
Causal convolutions ensure that each prediction relies only on current and previous frames, never future ones. This is crucial for real-time inference and allows MoViNets to function effectively in streaming environments.
- Implementing Ensemble Models For Better Generalization
Two identical models are trained independently with slight variations in frame input timing. Their predictions are then averaged, boosting overall accuracy without significantly increasing runtime.
These trained models are optimized and exported using TensorFlow Lite, enabling efficient deployment on mobile and edge devices with limited computational power.
Future Possibilities
As video data becomes more central to AI, MoViNets may expand into:
- AR/VR systems for real-time scene recognition
- Autonomous drones with onboard action detection
- Wearables that interpret human activities
- Gaming AI , offering smart responses based on video input
In all these scenarios, the ability to process video data quickly and accurately, without depending on a server or GPU cluster, is transformative.
Conclusion
MoViNets are revolutionizing video recognition. With their streamlined design, memory efficiency, and real-time capabilities, they offer a perfect blend of accuracy and practicality. From live streaming applications to mobile gaming and surveillance, these models are crafted to bring the power of video AI to devices everywhere.
Their performance proves that you don’t need bulky networks to process complex video content. As research continues and new variants emerge, we can anticipate even more refined and powerful versions of MoViNets in the near future.
If your goal is to bring high-quality video understanding to lightweight platforms, it’s time to take a serious look at MoViNets.