zfn9
zfn9
Machine learning offers a plethora of algorithms designed to analyze data, yet none match the accuracy of Support Vector Machines (SVMs). Originally developed for classification, SVMs have evolved into versatile tools used for regression, outlier detection, and text processing. Their ability to handle high-dimensional data makes them the go-to algorithm when other techniques fall short.
But what contributes to the exceptional performance of SVMs? The secret lies in their ability to create optimal boundaries between different groups in a dataset, achieving the highest possible classification accuracy.
Understanding the Core Concept of SVM
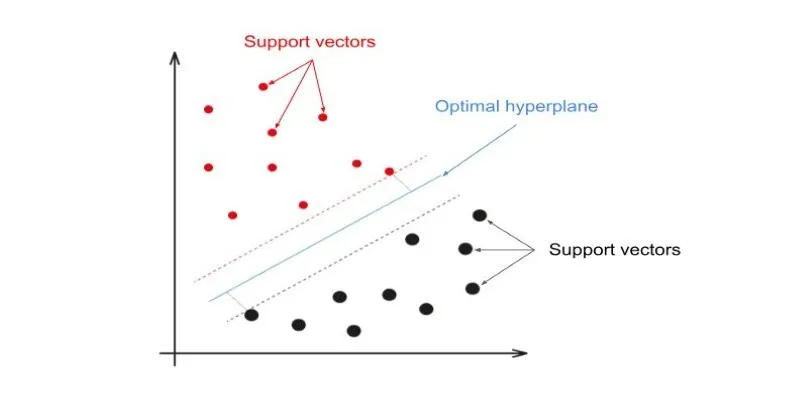
At its heart, a Support Vector Machine aims to find the best dividing line—or decision boundary—between various categories in a dataset. Imagine two categories of objects scattered on a graph. SVM strives to draw the most ideal line, known as a hyperplane, between them. The goal is to position this boundary so that the distance between each category’s nearest points is maximized. These nearest points are called “support vectors,” and they play a crucial role in determining the decision boundary.
This approach is called maximizing the margin. A larger margin helps the model generalize better to new data, minimizing the risk of misclassification. While cleanly separated data makes this task straightforward, real-world datasets often contain overlapping points, outliers, or non-linear distributions, complicating classification. Here, SVM’s strength in mapping data to higher dimensions becomes invaluable.
How SVM Handles Complex Data
Not all problems can be solved with a simple linear boundary. Some datasets require more sophisticated techniques to distinguish between various groups. SVM addresses this challenge using the kernel trick. This method allows SVM to transform data into higher dimensions, where it can be more easily separated by a boundary.
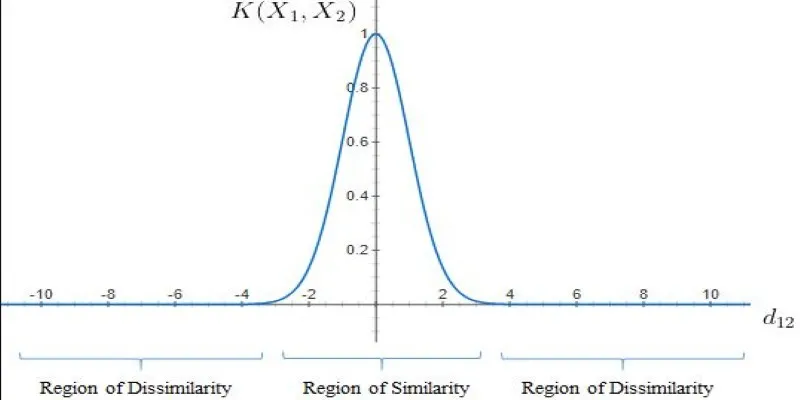
If a dataset seems inseparable in two dimensions, for instance, SVM can project it into a three-dimensional space where a clear boundary emerges. Common kernel functions include:
- Linear Kernel: Ideal for cases where data can be separated with a straight line.
- Polynomial Kernel: Useful for more complex relationships between data points.
- Radial Basis Function (RBF) Kernel: Effective for datasets with intricate patterns, creating flexible decision boundaries.
- Sigmoid Kernel: Occasionally used for neural network-inspired transformations.
By selecting the appropriate kernel, SVM can adapt to various data structures, making it a highly flexible machine learning tool.
Applications of SVM in the Real World
SVM’s versatility extends well beyond theoretical applications. Many industries utilize it to classify and predict patterns in large datasets. One of the most prevalent areas is image classification, where SVMs help distinguish between objects in photos, recognize handwriting, and detect medical anomalies in MRI scans. Their ability to handle high-dimensional data makes them especially effective in face detection and optical character recognition (OCR) tasks.
Another significant application is in text and speech recognition. Email spam filters, for example, often rely on SVMs to differentiate between legitimate and junk messages. Similarly, voice recognition systems use SVMs to identify spoken words and phrases with impressive accuracy.
In the financial sector, SVMs identify fraudulent transactions by detecting unusual spending patterns. Since fraud detection involves recognizing subtle deviations from normal activities, SVMs’ capability to handle high-dimensional data is particularly beneficial.
SVMs also play a vital role in healthcare. In disease prediction, they analyze medical records to identify early signs of conditions like cancer, heart disease, or diabetes. By training an SVM on extensive datasets containing past patient data, doctors can make informed predictions about a patient’s health risks.
Strengths and Limitations of SVM
SVMs offer several advantages, making them a preferred choice for many machine learning tasks. Their greatest strength is their robustness in handling high- dimensional data. Unlike other algorithms that falter with numerous features, SVM excels even when datasets contain thousands of variables.
Another significant advantage is their generalization ability. By maximizing the margin between classes, SVM often produces models that perform well on unseen data, reducing the likelihood of overfitting. Additionally, SVMs are effective even with relatively small datasets, making them an excellent choice when labeled data is limited.
Despite these strengths, SVMs are not without limitations. One major challenge is computational complexity. Training an SVM, especially with non-linear kernels on large datasets, can be time-consuming and require substantial computational resources. This makes it less practical for big data applications compared to algorithms like deep learning.
Another drawback is their sensitivity to noisy data. Since SVM relies heavily on support vectors, outliers can significantly impact the decision boundary. If the dataset contains excessive noise, SVM may struggle to generalize effectively.
Finally, selecting the right kernel function can be challenging. While SVM provides several kernel options, choosing the best one for a given dataset requires trial and error. An unsuitable kernel choice can lead to suboptimal results, necessitating domain expertise to fine-tune the model effectively.
Conclusion
Support Vector Machines remain a cornerstone of machine learning due to their exceptional accuracy, versatility, and ability to handle complex datasets. Whether classifying images, recognizing text, detecting fraud, or predicting diseases, SVMs have proven their reliability across various applications. Their strength lies in creating optimal decision boundaries, especially in high-dimensional spaces. Despite computational challenges, SVMs continue to be a preferred tool for many real-world tasks, particularly when data is limited or high precision is required. As machine learning evolves, SVMs remain highly relevant, serving as a powerful alternative to deep learning methods for numerous classification and regression problems.