zfn9
zfn9
When building a machine learning model, especially for classification tasks, metrics like accuracy are often relied upon. However, accuracy isn’t always sufficient—particularly when dealing with imbalanced classes. This is where metrics such as precision, recall, and the F-Beta score become essential. In this post, we’ll explore what the F-Beta score is, how it combines precision and recall, and how to use it effectively. This guide is designed to be simple, ensuring that even beginners can follow along.
Understanding the Basics: Precision, Recall, and Accuracy
Before delving into the F-Beta Score , it’s crucial to understand its foundational components.
Precision
Precision measures the accuracy of predicted positive instances. The formula is:
Precision = True Positives / (True Positives + False Positives)
Simply put, high precision indicates fewer false positives.
Recall
Recall assesses how many actual positive cases the model correctly identifies. Its formula is:
Recall = True Positives / (True Positives + False Negatives)
High recall means the model captures most relevant instances, even if it occasionally makes incorrect predictions.
Why Accuracy Is Not Always Enough
Accuracy, the ratio of correctly predicted instances to all instances, can be misleading, especially with imbalanced datasets. For instance, in a medical test where 98% of people don’t have a disease, a model predicting “no disease” for everyone will be 98% accurate but practically useless.
Defining the F-Beta Score
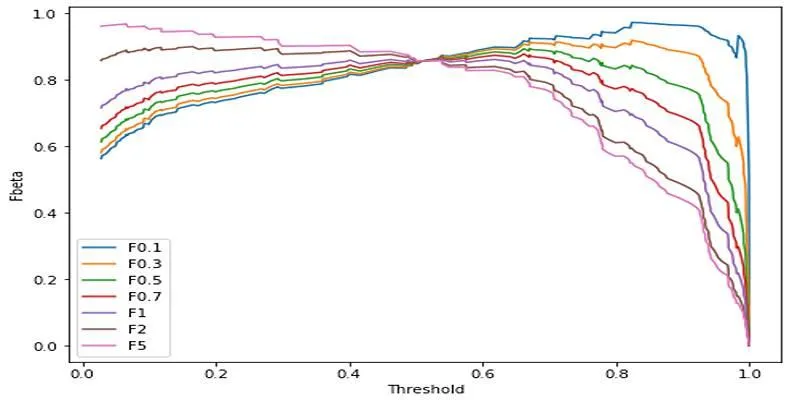
The F-Beta Score is a single, weighted metric that evaluates both precision and recall. This score is tailored for applications where either precision or recall is more critical.
The Formula for F-Beta Score
The general formula for the F-Beta Score is:
Fβ = (1 + β²) × (Precision × Recall) / (β² × Precision + Recall)
Here, β (beta) is a parameter that determines the relative importance of recall in the final score:
- If β = 1, it becomes the F1 Score, giving equal weight to precision and recall.
- If β > 1, recall is prioritized.
- If β < 1, precision is emphasized.
This formula allows developers to adjust focus based on the priorities of their specific use case.
When Should the F-Beta Score Be Used?
The F-Beta Score is most beneficial in scenarios where accuracy alone is insufficient for assessing model quality. It is widely used in applications involving imbalanced datasets and high-risk situations.
Common Use Cases
Several domains benefit significantly from the F-Beta Score:
- Medical Diagnosis : High recall is crucial to avoid missing true cases of a disease.
- Spam Detection : High precision is important to prevent genuine emails from being marked as spam.
- Credit Card Fraud : A balance is necessary, as both false positives and negatives carry financial risks.
- Information Retrieval : Systems like search engines may require custom F-Beta tuning for improved result relevance.
Choosing the Right Beta Value
Selecting an appropriate β value depends on the problem at hand. A well-chosen beta score enhances decision-making and ensures that model evaluation aligns with real-world needs.
Examples of Beta Values in Practice
- F0.5 Score: Emphasizes precision. Suitable for legal or fraud detection systems where false positives are costly.
- F1 Score: Balances precision and recall equally. Ideal for general-purpose classification tasks.
- F2 Score or F3 Score: Emphasizes recall. Commonly used in medical applications or disaster alerts, where missing a true case is more critical.
By adjusting β, developers can tailor the model to minimize either false positives or false negatives.
Real-World Applications of the F-Beta Score
Many practical machine learning tasks rely on metrics that accurately reflect a model’s performance. Below are examples highlighting the relevance of the F-Beta Score :
Medical Screening Systems
In healthcare, especially in disease detection, false negatives can lead to missed treatments. Hence, recall is prioritized, making the F2 or F3 Score more effective.
Email Filtering Tools
Email spam filters often use lower β values like F0.5 to minimize the risk of marking genuine emails as spam, prioritizing precision over recall.
How the F-Beta Score Is Computed in Practice
Modern machine learning libraries make calculating the F-Beta Score straightforward. One popular library, scikit-learn, offers built-in functionality:
from sklearn.metrics import fbeta_score
# y_true: actual labels
# y_pred: predicted labels
# beta: set according to your use case
score = fbeta_score(y_true, y_pred, beta=2)
print("F-Beta Score:", score)
This simple function allows machine learning engineers to integrate custom scoring directly into their model validation process.
Advantages of Using the F-Beta Score

Adopting the F-Beta Score offers benefits beyond mathematical accuracy, providing practical value in real-world decision-making.
Key Benefits:
- Customizable to specific priorities
- Effective for imbalanced datasets
- Combines two essential metrics into one score
- Guides model improvements and deployment decisions
- Suitable for sensitive or high-risk domains
By aligning model evaluation with actual business or societal impact, the F-Beta Score ensures smarter and more ethical deployment of machine learning solutions.
Limitations to Keep in Mind
While the F-Beta Score is powerful, it has limitations that require careful interpretation and context-aware tuning.
Things to Watch Out For:
- Incorrect β selection can mislead model improvements
- Unsuitable for regression tasks
- Needs to be used alongside other metrics for a comprehensive view
- In multiclass problems, averaging methods (macro vs. micro) must be chosen carefully
Thus, the F-Beta Score should complement other metrics, not replace them.
Conclusion
The F-Beta Score is a powerful and flexible evaluation metric that allows developers to assess model performance more meaningfully than relying on accuracy alone. By adjusting the beta value, developers can achieve a customized balance between precision and recall, making it ideal for various real-world applications. Whether minimizing false positives or false negatives is the goal, the F-Beta Score ensures the evaluation aligns with those priorities. It is particularly useful in domains with imbalanced data or high- stakes outcomes.