 zfn9
zfn9
Language is messy, unpredictable, and full of quirks that make it both beautiful and frustrating. For humans, understanding words in context is second nature. But for machines? It’s a challenge. That’s where Part of Speech Tagging steps in—it helps AI determine whether “run” is a verb in “I run daily” or a noun in “a home run.” Without this ability, Natural Language Processing would be hopelessly lost in ambiguity.
Whether powering chatbots, search engines, or grammar checkers, tagging lays the groundwork for machines to truly understand language. But how does it work, and why does it matter? Let’s break it down.
The Core Mechanism Behind Part of Speech Tagging
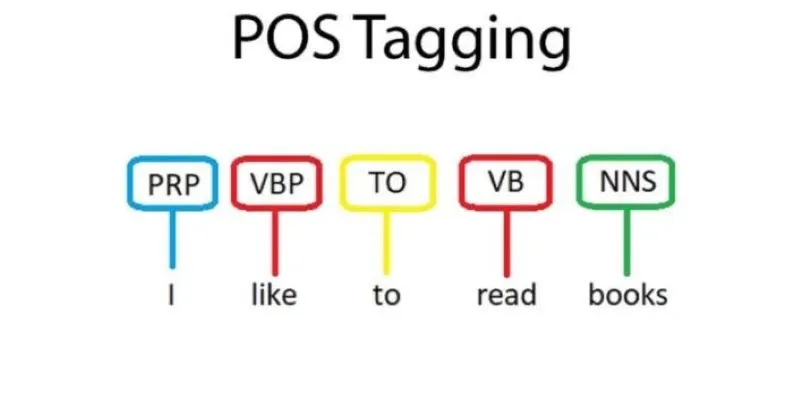
At its core, Part-of-Speech Tagging labels words grammatically in a sentence by their part in the sentence. For example, a sentence such as “The cat sleeps on the mat” is tagged to identify “cat” as a noun, “sleeps” as a verb, etc. The issue is context—most words fall into more than one category based on context.
For example, in “I can swim” and “Pass me the can,” the term “can” changes from a verb to a noun. To deal with such vagueness, tagging systems employ rule-based and probabilistic approaches.
Rule-based approaches rely on manually defined grammar rules to assign tags. While effective in controlled settings, they struggle with exceptions and unseen words. Probabilistic models, such as Hidden Markov Models (HMMs), predict a word’s tag based on likelihood and contextual patterns. Statistical methods improved tag accuracy considerably but needed large quantities of labeled data to perform effectively.
With the advent of Machine Learning, deep learning techniques such as Recurrent Neural Networks (RNNs) and Transformers have transformed tagging. Deep learning models examine whole sentences rather than single words, which helps them learn dynamically from context. With this advancement, Part-of- Speech Tagging has become more efficient, making it possible for applications such as speech recognition, machine translation, and sentiment analysis to carry out their functions with high accuracy.
Challenges in Achieving Accurate Part of Speech Tagging
Despite advancements in Part-of-Speech Tagging, achieving high accuracy remains a complex task due to linguistic ambiguity, diverse language structures, and evolving usage patterns.
Ambiguity in Language

Despite advances in Part-of-Speech Tagging, ambiguity remains a challenge. Homonyms, idioms, and informal expressions often break grammatical rules and confuse models. Words like “bank” (financial institution or riverbank) require context for correct tagging. Without deep Syntax Analysis, even sophisticated NLP systems struggle to determine meaning, leading to misclassifications in automated text processing and AI applications.
Linguistic Diversity
Many Natural Language Processing models are trained in English, limiting their effectiveness in structurally different languages like Japanese or Arabic. Some languages depend on morphology rather than word order, requiring adaptive tagging systems. Without multilingual datasets, Part-of-Speech Tagging struggles to generalize, reducing accuracy and making NLP less effective for global applications, especially in underrepresented linguistic communities.
Contextual Challenges in Syntax Analysis
Context plays a crucial role in Syntax Analysis, making it difficult for models to differentiate meanings. Consider “Time flies like an arrow” — “flies” could be a noun or a verb. Without Computational Linguistics models that analyze sentence structure holistically, taggers often misinterpret phrases, leading to inaccurate part-of-speech tagging and errors in downstream applications like translation or sentiment analysis.
Data Sparsity and Unknown Words
AI models struggle with data sparsity, encountering unfamiliar words in real- world applications. Rare words, slang, and evolving language trends hinder accuracy. When models lack training data, they rely on generalizations, leading to incorrect Part-of-Speech Tagging. Researchers are refining machine learning algorithms to better handle unknown words while ensuring computational efficiency and adaptability across diverse linguistic contexts.
Real-World Applications and the Future of Part of Speech Tagging
Despite its challenges, Part-of-Speech Tagging plays a pivotal role in modern Natural Language Processing systems. It serves as the foundation for machine translation, voice assistants, and sentiment analysis tools. Without it, AI- driven applications like chatbots, search engines, and grammar checkers would struggle to produce coherent and context-aware responses.
In medical and legal industries, where precision in language is paramount, tagging aids in document classification and automated summarization. By understanding the structure of legal contracts or medical reports, AI can help professionals process vast amounts of text efficiently.
Looking ahead, the future of Part-of-Speech Tagging will likely be shaped by increasingly sophisticated AI models. With advancements in deep learning, models like GPT and BERT continue to refine their ability to handle complex sentence structures. The integration of transformers allows AI to contextualize words with unprecedented accuracy, minimizing errors caused by ambiguity.
Moreover, the push for multilingual NLP means that tagging systems will become more adaptable across languages. Researchers are actively developing models that can learn from low-resource languages, ensuring that Computational Linguistics benefits a global audience rather than being limited to dominant languages like English.
The expansion of Part-of-Speech Tagging beyond text into speech and video processing is shaping the future of AI. Transcription and subtitle generation tools already use tagging to improve accuracy. As multimodal AI advances, tagging will play a crucial role in interpreting spoken language, bringing machines closer to near-human comprehension and contextual understanding.
Conclusion
Part of Speech Tagging is fundamental to Natural Language Processing, allowing machines to analyze text with structural and contextual accuracy. Categorizing words based on their roles powers essential applications like search engines, chatbots, and sentiment analysis. Challenges such as ambiguity and linguistic diversity persist, but advances in Computational Linguistics and deep learning continue to enhance tagging accuracy. The future points toward multilingual adaptation and integration into speech and video processing, making AI more versatile. As technology evolves, Part of Speech Tagging will remain a cornerstone of language-based AI, ensuring machines interpret human communication with greater precision and contextual awareness.























