zfn9
zfn9
Supervised learning is a cornerstone of artificial intelligence (AI) methodology. Historically, labeled data has been pivotal in aiding computers to make accurate predictions. In supervised learning, a machine learning model is trained using data that comes with predefined inputs and outputs, allowing the model to anticipate outcomes for unseen data.
For numerous real-world AI applications, such as email filtering and speech recognition, supervised learning is crucial. By learning from human input, systems can identify patterns, categorize data, and make highly accurate predictions. Without this technique, many of today’s AI technologies would not operate as effectively.
What is Supervised Learning?
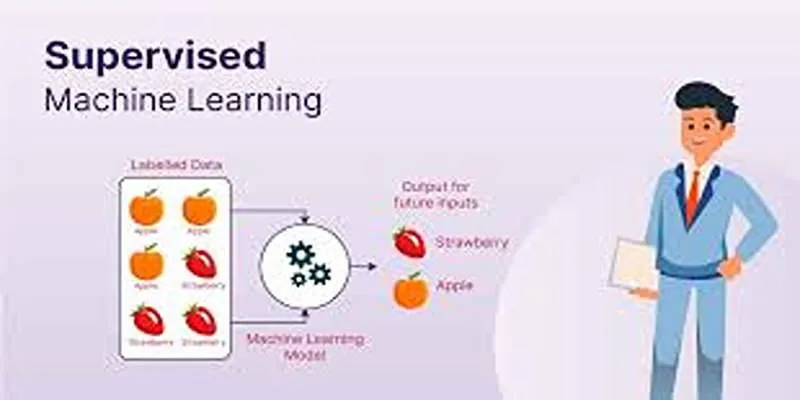
Supervised learning involves training a computer with labeled data. Each piece of training data includes the correct answer, which the model uses to learn and predict. The primary aim is to map input data to the correct output, thereby enabling the system to make informed decisions with new data.
For example, in image recognition tasks, models are trained with labeled pictures of cats and dogs. Each image is tagged with a label like “cat” or “dog,” enabling the model to distinguish between these animals. With sufficient training, the system can identify whether an unknown image depicts a cat or a dog.
The Process of Supervised Learning
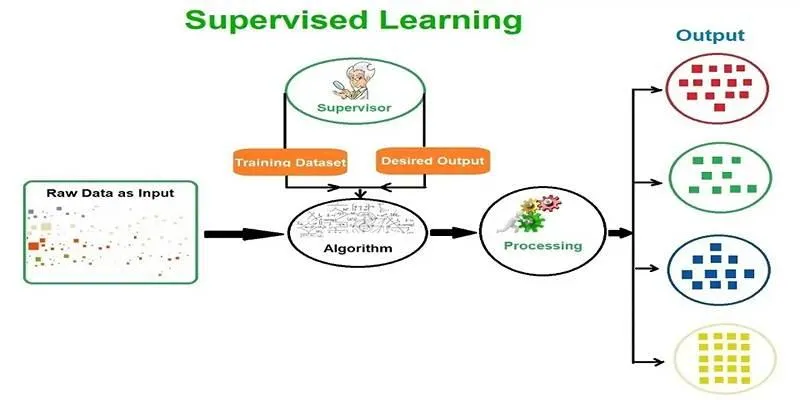
The process of supervised learning generally follows these steps:
- Data Collection : Assemble large sets of labeled datasets, comprising diverse inputs and corresponding correct outputs.
- Data Preprocessing : Clean and organize the data, which may involve removing duplicates, imputing missing values, or normalizing data.
- Model Selection : Choose an appropriate machine learning algorithm, such as decision trees, support vector machines, or neural networks, based on the problem.
- Training the Model : Train the model using labeled data. The algorithm learns by comparing predictions to actual labels and adjusting to minimize errors.
- Model Evaluation : Test the model on unseen data to assess its performance using metrics like accuracy, precision, recall, and F1 score.
- Model Optimization : Fine-tune the model based on evaluations to improve predictions, often by adjusting parameters or employing different training techniques.
Key Types of Supervised Learning Algorithms
Various algorithms are utilized in supervised learning, each with unique strengths and weaknesses depending on the data type and problem at hand. Here are a few commonly used ones:
Linear Regression:
Used for predicting continuous values, such as house prices based on features like square footage, number of rooms, and location.
Logistic Regression:
Despite its name, logistic regression is applied to classification problems, predicting binary outcomes like whether an email is spam.
Decision Trees:
Models that split data into subsets based on features, leading to predictions. They’re easy to interpret and understand.
Support Vector Machines (SVM):
Effective for classification tasks, especially when data isn’t linearly separable. They determine the optimal boundary (hyperplane) dividing classes.
Neural Networks:
Complex models suitable for tasks like image recognition and natural language processing, simulating the human brain to learn from extensive data.
Applications of Supervised Learning
Supervised learning boasts numerous real-world applications for tasks needing predictions or classifications. Here are some examples:
Email Filtering:
Utilized in spam filters, where algorithms trained with labeled emails (spam/non-spam) classify new emails based on learned patterns.
Image and Speech Recognition:
Essential in systems like facial recognition and speech-to-text applications, training on labeled images or audio samples for accurate predictions.
Medical Diagnosis:
Assists in healthcare by predicting diseases based on patient data. Models trained on historical medical data with labeled outcomes forecast future diagnoses.
Financial Prediction:
Predicts stock market trends, credit scores, or loan approvals by analyzing historical data.
Challenges in Supervised Learning
Despite its power, supervised learning presents challenges, including:
Data Quality:
Model accuracy relies heavily on data quality. Noisy, incomplete, or biased data can degrade performance.
Overfitting:
Occurs when a model learns training data details too well, including noise, resulting in poor performance on new data. Regularization and thorough evaluation are crucial.
Data Labeling:
Manually labeling large datasets can be time-consuming and costly, yet high- quality labeled data is vital for effectiveness.
Conclusion
Supervised learning underpins modern AI, enabling systems to make intelligent predictions and decisions. From image recognition to financial forecasting, its applications are vast. As technology progresses, supervised learning remains essential in developing smarter AI systems. Understanding its core concepts and applications enhances our appreciation of how it shapes our world and powers the technologies we rely on daily.