zfn9
zfn9
Ensuring efficient learning and fast convergence when training deep learning models can be challenging. This is where normalization techniques like Layer Normalization and Batch Normalization come into play. These methods are popular for stabilizing training and enhancing neural network performance. Although both aim to address the internal covariate shift and improve training efficiency, they differ in their approach to normalization.
In this article, we’ll explore the differences between Layer Normalization and Batch Normalization, how they function, and when each is preferable for deep learning applications.
The Basics of Normalization in Machine Learning
Before delving into Layer Normalization and Batch Normalization, it’s important to understand why normalization is used in machine learning, particularly in neural networks.
Deep learning models often experience internal covariate shifts, where the input data distribution to a layer changes during training. This shift can slow down training and hinder convergence to optimal solutions. Normalization addresses this issue by scaling and adjusting the inputs of each layer to maintain consistency during training. This results in faster convergence, reduced hyperparameter sensitivity, and a more stable model.
What Is Batch Normalization?
Batch Normalization (BN) was introduced to address the internal covariate shift. It normalizes a layer’s output by adjusting its activations using statistics (mean and variance) calculated over a mini-batch of data. Essentially, Batch Normalization standardizes the activations of each layer during training, ensuring inputs have a mean of zero and a standard deviation of one.

During training, Batch Normalization calculates the mean and variance of activations within a mini-batch, normalizes the data, and applies a learnable scaling factor and bias. This process stabilizes training by reducing internal covariate shifts.
Batch Normalization has gained popularity due to its ability to speed up training, reduce sensitivity to initial weights, and sometimes allow for higher learning rates, leading to improved performance. It is particularly effective in convolutional neural networks (CNNs) and other architectures where training speed is crucial.
However, Batch Normalization has limitations. Its reliance on mini-batch statistics can degrade performance when training on smaller batches or with highly variable batch sizes. It also struggles with tasks requiring high flexibility, such as recurrent neural networks (RNNs) or tasks with variable input sizes, like natural language processing.
What Is Layer Normalization?
In contrast, Layer Normalization (LN) normalizes activations across the entire input for each training example, rather than across a mini-batch. LN computes the mean and variance for each example independently, making it suitable for scenarios with small batch sizes or models that require flexibility in handling sequential data.
Layer Normalization is often used in recurrent neural networks (RNNs) and transformer architectures, where processing individual time steps independently is preferred. Unlike Batch Normalization, LN doesn’t rely on mini-batch statistics, avoiding issues with small batch sizes or variable input sizes.
Similar to Batch Normalization, Layer Normalization also applies a learnable scaling factor and bias post-normalization. This helps maintain the model’s ability to learn complex patterns without introducing biases in the normalized data.
Key Differences Between Layer Normalization and Batch Normalization
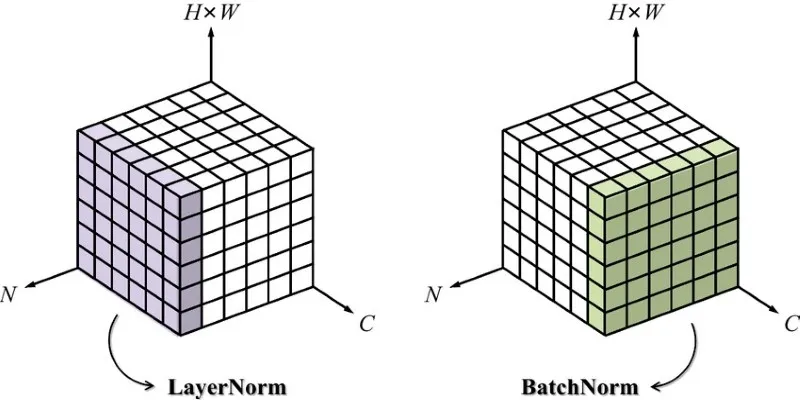
The main difference between Layer Normalization and Batch Normalization is how they compute normalization statistics. Batch Normalization normalizes over a mini-batch, while Layer Normalization normalizes across each input.
Batch-Level vs. Sample-Level Normalization:
Batch Normalization relies on statistics computed over a mini-batch, using multiple samples to calculate the mean and variance. In contrast, Layer Normalization computes these statistics over all units of a single layer per individual input. This distinction is crucial when choosing the right normalization technique based on your data and model.
Sensitivity to Batch Size:
Batch Normalization may struggle with small batch sizes due to unreliable statistics. In cases with very small batches or single-sample processing, it might not yield meaningful results. Layer Normalization, however, operates independently of batch size, offering more flexibility for variable batch sizes, such as in natural language processing tasks.
Use Cases:
Batch Normalization is highly effective in convolutional neural networks (CNNs), where large batches and independent samples per batch are common. It is widely used in computer vision and tasks with fixed input sizes.
On the other hand, Layer Normalization is ideal for tasks involving sequential data, like time series prediction or natural language processing, especially in models like RNNs and transformers, where each sample is processed independently.
Training Speed and Efficiency:
Batch Normalization can accelerate training by stabilizing learning rates, but it requires additional computation to maintain mini-batch statistics. Layer Normalization, by focusing on each sample, may lead to slightly slower training in some scenarios but is generally more stable and less dependent on batch size.
Conclusion
Both Layer Normalization and Batch Normalization play crucial roles in optimizing deep learning models, but their applications vary based on the task. Batch Normalization is ideal for tasks with large, consistent batch sizes, especially in CNNs. Layer Normalization excels in sequence-based models like RNNs or NLP tasks, where flexibility and smaller batches are essential. Understanding their differences helps you choose the right technique for better training stability and efficiency.