zfn9
zfn9
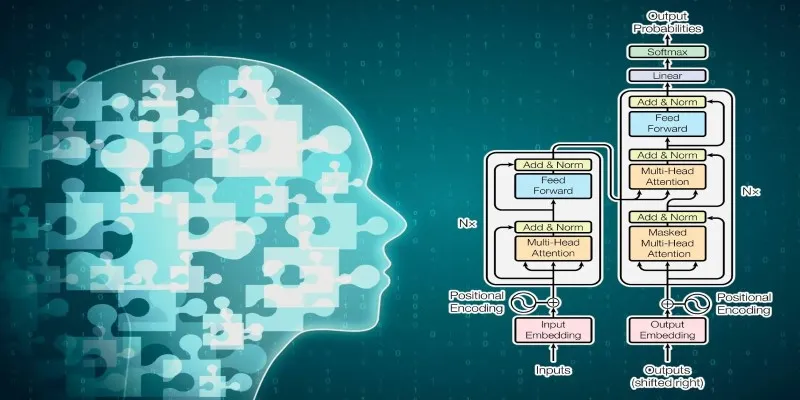
When BERT arrived, it transformed the way machines comprehend language. It revolutionized natural language processing and quickly became the gold standard. Integrated into a myriad of applications, from online searches to translation tools, BERT introduced deep bidirectional learning for a more accurate understanding of sentence structure.
However, it was not without limitations—slow training times, high resource demands, and inadequate performance with lengthy texts. Today, new models surpass BERT in many aspects. These are not just upgrades; they mark a shift in the foundation of language modeling.
What Made BERT a Game-Changer?
BERT’s architecture was unique as it implemented bidirectional attention. Instead of processing sentences linearly, BERT considered all words simultaneously. This feature enhanced its understanding of context. For instance, BERT could discern whether “bank” referred to a riverbank or a financial institution based on nearby words.
Its widespread adoption began with Google integrating it into their search engine. Open-source versions soon followed, and the research community started building upon its base. Models like RoBERTa refined the training process, while others, such as DistilBERT, optimized it for speed. BERT’s format became the go-to for language tasks, from classification and sentiment detection to question answering.
Despite its success, BERT had limitations. Its pre-training task—masked language modeling—was effective for learning grammar and structure but didn’t truly mimic language usage. BERT struggled with producing text and summarizing spontaneously, limiting its applicability. Another setback was its fixed input length, posing a disadvantage for processing longer documents.
As user demands increased for models capable of handling broader contexts and more complex tasks efficiently, the need for a true BERT alternative became evident.
Emergence of Transformer-Based Alternatives
Models such as T5, a transformer that reframes all language tasks as text-to-text, have emerged as noteworthy BERT alternatives. Unlike BERT, which requires separate configurations for classification, translation, or summarization, T5 treats all tasks as problems of generating text based on input, making it adaptable and easier to use.

Other significant advancements include the GPT series. GPT-2 and GPT-3, primarily designed for text generation, also excelled in comprehension tasks. These models use a unidirectional approach, predicting the next word in a sequence. Despite its simplicity, this model has proven effective for deep language understanding. GPT-3's capability to handle a variety of tasks with minimal instruction set a new standard.
DeBERTa, a model similar to BERT, improves the separation of content and positional information, boosting performance in reading comprehension and classification. Despite being similar in size to BERT, DeBERTa achieves higher accuracy on many standard tests.
These models not only deliver superior results but also align more closely with real-world language usage. They can manage longer sequences, respond with text, and adapt to varied inputs, eliminating the need for custom layers for each task.
Why Are These Models Superior?
New models excel where BERT falters. Notably, their training methods reflect human language use more closely. Instead of predicting masked words, they learn to produce full sequences, enabling better handling of tasks such as summarizing or generating responses.
T5's uniform approach—everything as a text input and a text output—reduces the need for custom architecture. GPT models excel at producing fluent, human-like text, making them ideal for systems requiring conversational replies or content generation.
BERT's fixed input size was a limitation, restricting its ability to process large blocks of text. Newer models employ efficient attention mechanisms or sparse patterns to process longer inputs. Models like Longformer and BigBird introduced methods for handling lengthy documents, and their ideas have been adopted by more recent models.
Smaller versions of these newer models, such as T5-small and GPT-2 medium, offer robust performance with minimal resource demands. They can be used in devices or apps that require rapid responses without needing powerful servers.
The new language models understand instructions more effectively, generate usable content, and adapt to a broader range of tasks. Their flexible structure and reliable results have made them the preferred choice over BERT.
The Future Beyond BERT
While BERT’s influence will continue, it is no longer the default model. T5, DeBERTa, and GPT-3 are better suited to today’s challenges. They can process longer texts, respond more naturally, and require less task-specific tuning. As these models improve, we are moving towards systems that understand and respond to language with more depth and less effort.

Newer models prioritize transparency. Open-source projects like LLaMA and Mistral deliver high performance without dependency on massive infrastructure. These community-driven models match or exceed the results of older models while being easier to inspect and adapt.
BERT now stands as a milestone in AI history, marking significant progress. However, it is no longer the best tool for modern systems. The industry has evolved, and the models replacing BERT are not just improvements—they’re built on innovative ideas, better suited to contemporary language use.
Conclusion
BERT revolutionized how machines understand language, but it is no longer the front-runner. Language models such as T5, GPT-3, and DeBERTa outperform BERT in flexibility, speed, and practical use. They can handle longer inputs, adjust to tasks easily, and generate more natural responses. While BERT paved the way, today’s models are tailored for real-world demands. The shift has occurred—BERT has been replaced, and a new standard in language modeling is already in motion.