zfn9
zfn9
Deep learning has revolutionized the way machines process information, but not all models function the same. Two giants in the field—Transformers and Convolutional Neural Networks (CNNs)—approach problems differently and are pivotal in shaping the future of artificial intelligence (AI). CNNs, inspired by human vision, excel in image recognition, while Transformers, designed for language processing, are redefining AI’s ability to understand context.
Their influence is expanding beyond their original domains, sparking debates over which model is superior. The answer isn’t straightforward. Understanding their differences is not just for researchers; it’s key to unlocking AI’s full potential. Let’s break down what sets them apart and where they shine.
Understanding the Core Architecture
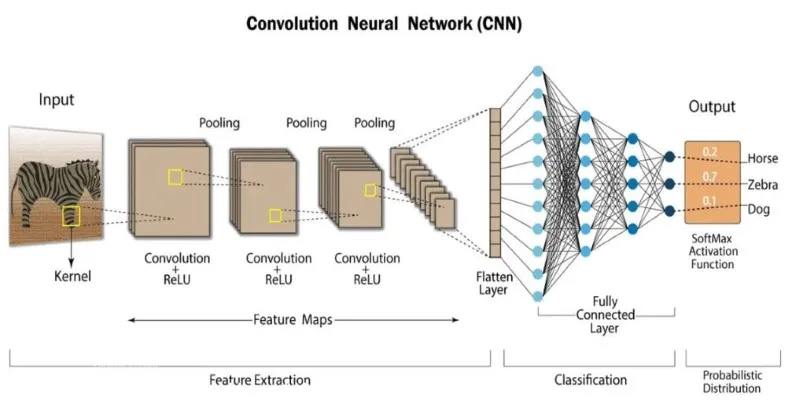
CNNs have been at the forefront of computer vision for years, drawing inspiration from how the human brain processes visual information. Convolutional layers are used to extract features from images, identifying edges, shapes, and textures in a hierarchical manner. Pooling layers reduce dimensionality while preserving essential features, enhancing computational efficiency. The final fully connected layers recognize objects based on extracted patterns. This design makes CNNs powerful in spatially aware tasks like medical imaging and face recognition.
Transformers, on the other hand, were initially intended for sequential data but have proven to be extremely adaptable. Their central innovation is the self-attention mechanism, which allows them to assign weights to the importance of various elements within a sequence. Unlike CNNs that work based on spatial hierarchies, Transformers can process all input data simultaneously, capturing long-range dependencies efficiently. This capability is particularly useful in language processing, where context is crucial. Unlike older recurrent networks, Transformers can process entire sequences in parallel, significantly speeding up training times. Their scalability has enabled them to surpass older models in tasks ranging from machine translation to text generation. Although initially developed for natural language processing, Transformers have since been applied to domains like protein folding predictions and image recognition through Vision Transformers (ViTs).
Strengths and Limitations
CNNs are excellent at recognizing visual patterns, making them indispensable for image classification, object detection, and facial recognition. Their ability to break down images into smaller patterns and process them hierarchically enables precise and efficient classification. CNNs are also computationally efficient with structured data, making them ideal for real- time applications like self-driving cars and surveillance systems. However, CNNs struggle with understanding sequential relationships in data. Their reliance on fixed-size filters makes it difficult to capture long-distance dependencies, limiting their effectiveness in tasks like language modeling.
Transformers excel in tasks requiring context awareness. Their self-attention mechanism allows them to understand relationships between words in a sentence, revolutionizing natural language processing. They have also begun to challenge CNNs in image recognition, with Vision Transformers outperforming traditional models in some cases. However, their biggest drawback is their computational cost. Training large-scale Transformer models requires vast amounts of data and processing power, making them resource-intensive. Additionally, their decision-making process is often difficult to interpret, posing challenges in applications where transparency is crucial. Despite these limitations, Transformers have expanded AI capabilities, opening new possibilities beyond text processing.
Real-World Applications
CNNs continue to dominate the field of computer vision, with applications in healthcare, security, and autonomous systems. They are widely used in medical imaging to detect abnormalities in X-rays and MRIs. Self-driving cars rely on CNNs for object detection and scene understanding, ensuring safe navigation. Facial recognition systems, fraud detection tools, and artistic style transfer also heavily depend on CNN-based architectures. Despite growing competition from Transformers, CNNs remain the preferred choice for visual processing tasks requiring efficiency and high accuracy.
Transformers have transformed natural language processing. They power advanced chatbots, real-time language translation tools, and AI-generated content. Models like GPT have revolutionized content creation, enabling AI to write human-like text with remarkable coherence. Beyond language, Transformers impact areas like drug discovery and financial forecasting. Their ability to analyze patterns across vast datasets makes them useful for predicting market trends and optimizing logistics. Vision Transformers are also challenging CNN dominance in image recognition, with some models achieving state-of-the-art performance in classification tasks. As research continues, the role of Transformers in AI is expected to expand further, making them a critical component of future technological advancements.
Evolving Trends in AI: The Future of Transformers and CNNs
Deep learning is rapidly advancing, with CNNs and Transformers evolving to meet new challenges. Researchers are developing hybrid models that blend CNNs’ feature extraction with Transformers’ attention mechanisms, enhancing image recognition and efficiency. Vision Transformers (ViTs) are already competing with CNNs in computer vision, indicating a potential shift in AI model dominance. Meanwhile, improvements in hardware, such as AI accelerators, are helping mitigate the high computational demands of Transformers, making them more accessible.

CNNs remain indispensable for tasks requiring speed and spatial awareness, while Transformers continue to redefine NLP and sequential data processing. As AI applications expand, both architectures will likely coexist, each optimizing performance in its specialized domain. The future will see greater integration of these models, with AI systems leveraging their strengths to achieve unprecedented accuracy and efficiency. The ongoing evolution of deep learning ensures a dynamic and competitive AI landscape.
Conclusion
Both Transformers and Convolutional Neural Networks are revolutionary in their own right, each excelling in different domains. CNNs remain the gold standard for image-related tasks, leveraging their hierarchical structure to extract features efficiently. Meanwhile, Transformers have changed the landscape of NLP and are now expanding into new areas, offering unparalleled scalability and flexibility. Choosing between the two depends on the problem at hand—CNNs for structured image data and Transformers for complex dependencies in text and beyond. As AI advances, the interplay between these models will likely shape the future of deep learning.