zfn9
zfn9
Machines have long struggled to truly make sense of human language, often tripping over nuance, ambiguity, and context. Generative Pre-training (GPT) changes that by teaching models to read and predict words the way people write and speak. Unlike models built for single tasks, GPT learns from vast amounts of text to grasp patterns, tone, and meaning, applicable to various uses. This shift has made AI far more conversational and capable of understanding the intent behind words. Here’s an explanation of how GPT helps machines understand language more effectively and where its strengths and weaknesses lie.
How Does Generative Pre-training Work?
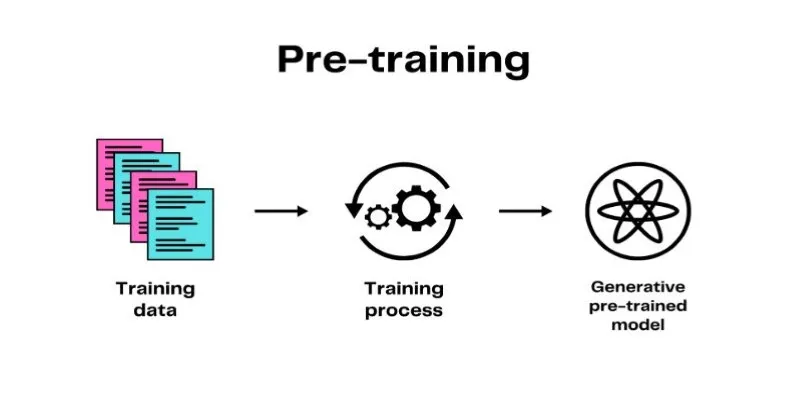
Generative Pre-training works in two main stages: pre-training and fine-tuning. During pre-training, the model reads through massive collections of text, learning by predicting the next word in a sentence. This process helps the model pick up grammar, context, tone, and subtle writing habits. It becomes comfortable with everything from casual conversation to technical writing, connecting words and ideas in meaningful ways. Over time, it builds a strong statistical sense of how language actually works.
In the fine-tuning stage, the model is given a smaller, carefully labeled dataset tailored to a specific job, like spotting sentiment in reviews or summarizing reports. Fine-tuning adjusts the model’s knowledge for the task at hand without erasing what it learned during pre-training. This two-step approach is much faster and more efficient than training from scratch. Since the model already “speaks the language,” it only requires minor adjustments to perform a wide range of tasks effectively.
Advantages of GPT for Natural Language Understanding
GPT offers significant advancements in natural language understanding:
-
Contextual Understanding: GPT captures context by considering entire sequences of words, resolving ambiguity in phrases, and understanding nuance in longer texts.
-
Versatility: A single GPT model can adapt to various tasks with minimal adjustments. It excels in sentiment analysis, translation, topic detection, and summarization, eliminating the need for separate models for each task.
-
Handling Unstructured Text: GPT deals well with informal or inconsistent text, tolerating slang, typos, and omitted words better than earlier systems.
-
Few-shot Learning: GPT can learn tasks from just a few examples, contrasting with earlier models that required thousands of labeled examples for good accuracy.
Limitations and Challenges
Despite its strengths, GPT has limitations:
-
Lack of True Understanding: GPT predicts words based on patterns without understanding underlying concepts, leading to errors with sarcasm, irony, or cultural references.
-
Bias: GPT can reproduce biases present in training data, leading to inappropriate outputs. Reducing these biases requires careful data selection and additional adjustments.

-
Resource Intensity: Large GPT models require significant computing power and energy, making them expensive to train. While pre-trained models are more accessible, deploying them still requires technical expertise.
-
Confident but Inaccurate Outputs: GPT can produce fluent text that appears plausible even when incorrect. This makes human oversight crucial for critical tasks.
How Does GPT Compare to Traditional Methods?
Before GPT, natural language understanding relied on rule-based systems or narrow machine learning models:
-
Rule-based Systems: Depended on hand-crafted instructions, handling well-defined tasks but failing with unexpected language patterns. They were rigid and hard to scale.
-
Machine Learning Models: Learned from data but were task-specific. Each new task required collecting and labeling new data, which was time-consuming and costly.
GPT overcomes these limitations by learning broad language patterns during pre-training, allowing reuse for different tasks with minimal fine-tuning. Its ability to handle few-shot or zero-shot tasks sets it apart from older methods.
However, traditional methods still have a place. For tightly controlled tasks, smaller, task-specific models can be preferable due to their predictability and lower computing power requirements.
Conclusion
Generative Pre-training has unlocked new possibilities in natural language understanding, providing models with a broad linguistic foundation. GPT’s adaptability, contextual understanding, and ability to handle messy inputs make it far more capable than earlier methods. However, its reliance on patterns, tendency to reproduce bias, and resource demands mean it’s not a perfect solution. GPT represents progress in making machines interact more naturally with people, but careful oversight and refinement remain essential. As technology advances, GPT’s role in enhancing language-based systems will continue to grow.