zfn9
zfn9
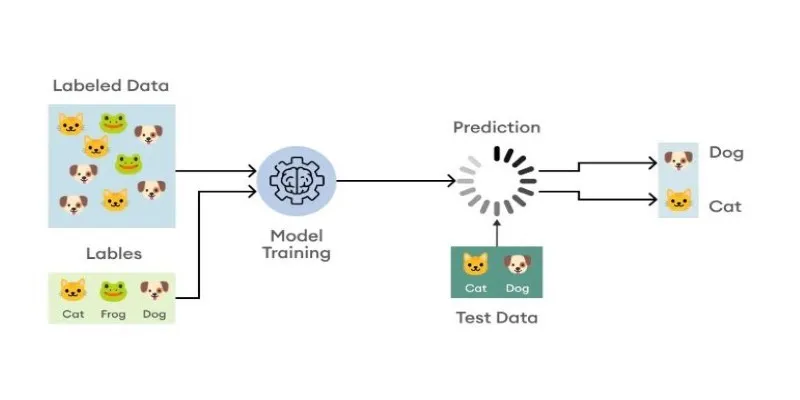
In today’s data-driven world, businesses and developers often encounter the challenge of classifying text without a large amount of labeled data. Traditional machine learning models heavily depend on annotated examples, which can be both time-consuming and costly to prepare. This is where zero- shot and few-shot text classification techniques come into play.
With Scikit-LLM, an innovative Python library, developers can perform high- quality text classification tasks using large language models (LLMs) even when labeled data is limited or entirely absent. Scikit-LLM integrates seamlessly with the popular scikit-learn ecosystem, allowing users to build smart classifiers with just a few lines of code.
This post explores how Scikit-LLM facilitates zero-shot and few-shot learning for text classification, highlights its advantages, and provides real-world examples to help users get started with minimal effort.
What Is Scikit-LLM?
Scikit-LLM is a lightweight yet powerful library that acts as a bridge between LLMs like OpenAI’s GPT and scikit-learn. By combining the intuitive structure of scikit-learn with the reasoning power of LLMs, Scikit-LLM enables users to build advanced NLP pipelines using natural language prompts instead of traditional training data.
It supports zero-shot and few-shot learning by allowing developers to specify classification labels or provide a handful of labeled examples. The library automatically handles prompt generation, model communication, and response parsing.
Zero-Shot vs. Few-Shot Text Classification
Understanding the difference between zero-shot and few-shot learning is crucial before diving into the code.
Zero-Shot Classification
In zero-shot classification , the model does not see any labeled examples beforehand. Instead, it relies entirely on the category names and its built-in language understanding to predict which label best fits the input text.
For instance, a model can categorize the sentence “The internet is not working” as “technical support” without any prior examples. It leverages its general knowledge of language and context.
Few-Shot Classification
Few-shot classification involves providing the model with a small set of labeled examples for each category. These samples guide the model to better understand the tone and context of each label, enhancing accuracy.
For example, by showing the model samples like:
- “The bill I received is incorrect” – billing
- “My modem is broken” – technical support
The model can better classify similar incoming messages with higher precision.
Installing Scikit-LLM

To start using Scikit-LLM, you need to install it via pip:
pip install scikit-llm
Additionally, you will need an API key from a supported LLM provider (such as OpenAI or Anthropic) since the library relies on external LLMs to process and generate responses.
Zero-Shot Text Classification Example
One of the standout features of Scikit-LLM is how effortlessly it performs zero-shot classification. Below is a basic example that demonstrates this capability.
Sample Code:
from sklearn.pipeline import make_pipeline
from skllm.models.gpt import GPTClassifier
X = [
"Thank you for the quick response",
"My payment didn’t go through",
"The app keeps crashing on my phone"
]
labels = ["praise", "billing issue", "technical issue"]
clf = GPTClassifier(labels=labels)
pipeline = make_pipeline(clf)
predictions = pipeline.predict(X)
print(predictions)
In this example, no training data is provided. The classifier uses its understanding of the label names and the input texts to assign the most suitable category.
Few-Shot Text Classification Example
To further refine the model’s performance, developers can switch to few-shot learning by adding a few examples for each category.
Sample Code:
examples = [
("I love how friendly your team is", "praise"),
("Why was I charged twice this month?", "billing issue"),
("My screen goes black after I open the app", "technical issue")
]
clf = GPTClassifier(labels=labels, examples=examples)
pipeline = make_pipeline(clf)
X = [
"I really appreciate your help!",
"The subscription fee is too high",
"It won’t load when I press the start button"
]
predictions = pipeline.predict(X)
print(predictions)
By providing just one example per label, the model gains a clearer idea of what each category represents. This technique often results in improved outcomes in real-world scenarios.
Why Use Scikit-LLM for Text Classification?
Scikit-LLM simplifies LLM usage and offers numerous benefits for developers and businesses alike.
Key Benefits:
- No Training Required: Models can be used instantly without the need for large training datasets.
- Works with Minimal Data: Just a few examples are enough to get started.
- Seamless Integration: Easily integrates into existing scikit-learn pipelines.
- Multi-Model Support: Compatible with popular LLMs like GPT, Claude, and others.
- Rapid Prototyping: Ideal for quickly testing new ideas and applications.
Common Use Cases
Scikit-LLM can be applied across various industries and workflows. Below are some practical use cases:
- Customer Support: Automatically tag or sort incoming support tickets.
- Social Media Monitoring: Classify tweets or comments as positive, negative, or neutral.
- Email Categorization: Route emails to the appropriate department (sales, support, etc.).
- Survey Analysis: Group responses into themes without manual labeling.
- Content Moderation: Detect and flag offensive or inappropriate content.
Best Practices for Better Results

While Scikit-LLM simplifies the classification process, following a few best practices can help achieve more reliable results.
Tips:
- Use Clear and Distinct Labels: Avoid labels that overlap in meaning.
- Write Concise Examples: Keep few-shot examples short and to the point.
- Limit Category Count: Too many labels can confuse the model.
- Stay Domain-Relevant: Use examples and labels relevant to the target domain.
Challenges and Considerations
Despite its ease of use, Scikit-LLM does have some limitations users should be aware of:
- Dependence on External APIs: Requires internet access and API keys for LLMs.
- Cost of Usage: API calls may incur charges, depending on the provider.
- Response Time: Processing times may vary based on model size and queue delays.
- Privacy: Sensitive data should be handled carefully due to external model use.
These concerns can be addressed by choosing the right model provider and following responsible AI practices.
Conclusion
Scikit-LLM offers a modern, efficient way to leverage the power of large language models in text classification workflows. By supporting both zero-shot and few-shot learning, it eliminates the need for large labeled datasets and opens the door to rapid, flexible, and intelligent solutions. Whether the goal is to classify customer feedback, analyze social posts, or organize support tickets, Scikit-LLM enables developers to build powerful NLP tools with just a few lines of Python code. Its seamless integration with scikit-learn makes it accessible even to those new to machine learning.