zfn9
zfn9
Few-shot learning has long been a challenge in artificial intelligence. Training a model with just a few labeled examples is appealing, especially when labeled data is scarce or costly. However, traditional methods often fall short. This is where SetFit steps in with an innovative approach.
SetFit transforms the process by eliminating the need for prompt engineering or massive labeled datasets. It leverages sentence transformers and contrastive learning, making the process both efficient and effective. This marks a significant shift in how we adapt language models with minimal supervision.
How SetFit Works: Sentence Transformers and Contrastive Learning
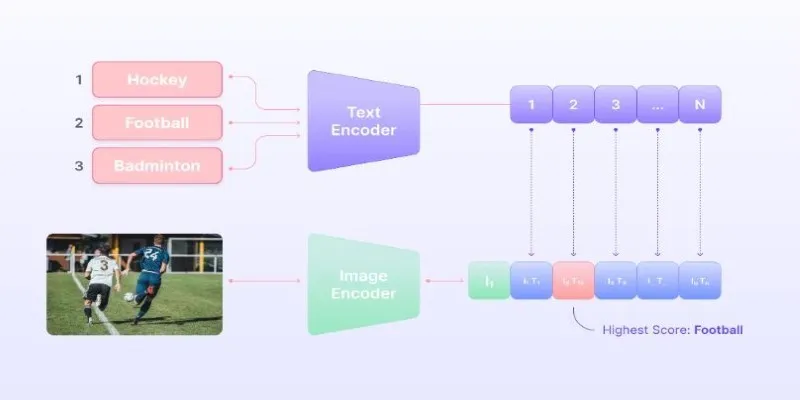
SetFit, which stands for “Set-based Few-shot fine-tuning,” trains text classification models without handcrafted prompts or large-scale generative models. Traditional few-shot methods often rely on prompts that can introduce variance and limit flexibility. SetFit avoids this by using sentence transformers, which map sentences into dense vector representations, combined with contrastive learning. This technique teaches the model to bring similar pairs closer and push dissimilar pairs apart in the embedding space.
Essentially, SetFit fine-tunes pre-trained sentence transformers using a small number of labeled examples. These transformers, like all-MiniLM-L6-v2, are adept at capturing sentence semantics. The fine-tuning process focuses on aligning sentence pairs so that sentences from the same class appear more similar. For instance, two reviews expressing positive sentiments are recognized as semantically close, even if the wording differs.
Contrastive learning enhances efficiency. Instead of treating each example in isolation, the model learns from example pairs. This approach significantly expands the learning signal without needing more labeled data. A mere 8 labeled examples can create dozens of positive and negative pairs, improving generalization even with limited input.
Training Without Prompts: A Clearer Path to Adaptation
Prompt engineering, which involves crafting textual instructions for models, has dominated recent few-shot learning efforts, particularly with large language models like GPT-3. However, this method has several drawbacks. Prompts are sensitive to small changes, and effective prompts are difficult to design, often requiring domain expertise or trial-and-error.

SetFit eliminates the need for prompts. It doesn’t wrap inputs into task-specific questions or rely on the model’s ability to interpret natural language instructions. Instead, it focuses on learning from sentence embeddings, simplifying adaptation to new tasks. You need only a few labeled examples, with no template writing required.
This makes SetFit especially appealing in low-resource settings or niche domains where prompt tuning fails or generative models produce unreliable results. The model’s architecture allows direct fine-tuning for classification tasks like spam detection, customer feedback categorization, or intent identification without the overhead of prompt optimization or multiple inference passes.
Performance, Speed, and Practical Use
SetFit is optimized for speed and efficiency. By using sentence transformers and avoiding expensive generation steps, it operates efficiently even on CPUs, making it ideal for deployment in environments with limited hardware or where real-time performance is crucial.
Despite its simplicity, SetFit performs well across various benchmarks. On datasets like SST-2, TREC, and AgNews, SetFit matches or exceeds prompt-based few-shot methods, often with just 8 to 16 examples per class. Its robustness across different domains and languages is enhanced by the generalization capabilities of sentence transformers.
Training time is minimal: you can fine-tune a SetFit model in under a minute on a modern laptop. In contrast, prompt-based methods often require multiple testing rounds and prompt fine-tuning, with inference times growing with model size.
Another advantage is the production of compact, task-specific models. These models are much smaller than generative LLMs and can be deployed easily in production systems. There’s no need for a large model when a lightweight transformer can achieve similar accuracy with fewer resources.
Real-World Value and Limitations
SetFit offers a more accessible path for organizations and developers who want to apply AI to their data but can’t invest in large-scale labeling or infrastructure. It’s particularly useful for internal applications where domain-specific labels are scarce, such as customer service, internal ticket classification, HR feedback tagging, or small-scale document categorization.

That said, it’s not a silver bullet. SetFit excels in classification tasks but doesn’t support sequence generation or complex tasks like summarization or dialogue. It also relies on the sentence transformer backbone’s quality. If the transformer doesn’t capture relevant data nuances, performance may plateau. In specialized domains, some domain-specific pretraining might be necessary.
Data imbalance poses another challenge. While contrastive learning benefits from balanced sets of positive and negative pairs, skewed class distributions may require careful sampling to maintain effectiveness. However, these trade-offs are manageable compared to the overhead and uncertainty of prompt-based learning.
Conclusion
SetFit offers a simpler, faster, and more efficient approach to few-shot learning. By bypassing prompts and leveraging sentence transformers and contrastive learning, it makes training text classifiers straightforward and scalable. The method eliminates much of the trial-and-error in prompt engineering, providing a consistent way to adapt to new tasks with just a few labeled examples. It performs well, runs fast, and doesn’t demand heavy infrastructure or constant tuning. For many applications, SetFit is a refreshing alternative that keeps things focused, adaptable, and resource-friendly—all while getting the job done.