zfn9
zfn9
Data is the new oil fueling businesses, governments, and innovations worldwide. However, handling massive amounts of it isn’t as simple as storing files on a computer. Traditional databases struggle with sheer volume, speed, and complexity. That’s where Hadoop steps in—a game-changing framework designed to store, process, and analyze enormous datasets efficiently.
Designed for scalability, Hadoop spreads data over many machines, making it fast and reliable. Whether it’s social media analysis, financial transactions, or medical data, Hadoop drives industries that depend on big data. But what makes it so powerful? Let’s demystify how Hadoop turns raw data into valuable insights.
The Core Components of Hadoop
Fundamentally, Hadoop is comprised of two fundamental components: the Hadoop Distributed File System (HDFS) and MapReduce.
Hadoop Distributed File System (HDFS)
HDFS is the system’s storage layer. It aims to store enormous volumes of data across multiple servers, referred to as nodes, in a manner that makes the data fault-tolerant yet accessible. When data is saved in HDFS, it is divided into pieces (blocks) and replicated over several machines. This guarantees that even if one of the nodes is lost, data is still retrievable due to the existence of replicas of every block on other nodes.
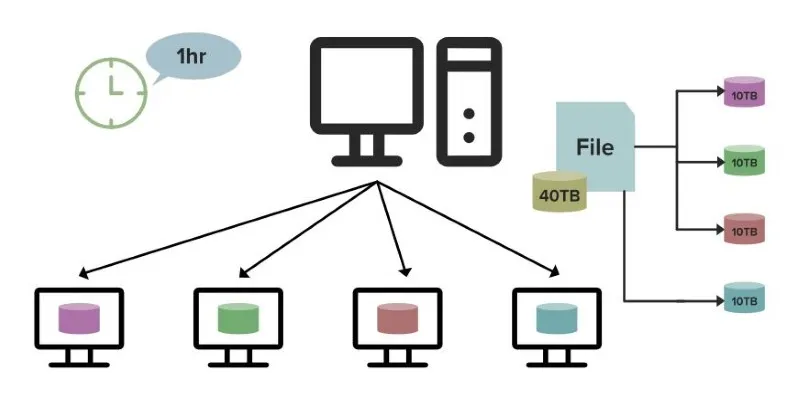
This makes HDFS a perfect fit for big data storage. Whether structured data, such as customer transactions, or unstructured data, like videos, HDFS can handle it with ease. Distributing data across several machines prevents bottlenecks in processing and retrieval, which is particularly important when handling large datasets.
MapReduce
MapReduce is Hadoop’s compute layer. It is a programming model for processing data in parallel on clusters of machines by breaking the job into smaller parts and processing each of them. The “Map” phase shreds the data into key- value pairs, operates on it, and distributes the effort. The “Reduce” phase gathers the outcomes, operates further on them, and outputs the final result.
What is so powerful about MapReduce is that it can handle massive amounts of data at mind-boggling speeds. Its parallelism ensures that, rather than processing data sequentially on a single machine, the work is split up among numerous machines, accelerating the process considerably.
Hadoop’s Scalability
One of the primary reasons Hadoop has become so popular is its scalability. Unlike traditional data storage systems that require huge investments in physical infrastructure, Hadoop is designed to work on commodity hardware. This means that anyone can start with a small cluster of machines and, as their data grows, simply add more machines to scale the system horizontally.
This scalability is crucial for businesses, especially as they accumulate more data over time. With Hadoop, there’s no need for a large upfront investment in high-end storage devices. Instead, you can start small and grow as needed, making it an affordable solution for organizations of all sizes.
Hadoop Ecosystem
While Hadoop’s two main components—HDFS and MapReduce—provide the basic functionality, the ecosystem around Hadoop is what truly makes it versatile and powerful. Over time, a wide array of projects and tools have been built around Hadoop to extend its capabilities. Some of the most popular tools in the Hadoop ecosystem include:
Hive: A data warehouse system built on top of Hadoop that allows you to query data using SQL-like syntax, making it easier for those familiar with traditional databases to interact with big data.

Pig: A high-level platform for creating MapReduce programs that simplify coding by using a language called Pig Latin, which is easier to write and understand than raw MapReduce code.
HBase: A non-relational database built on top of HDFS, offering real-time access to large datasets. HBase is designed for random read and write access, unlike HDFS, which is optimized for batch processing.
YARN (Yet Another Resource Negotiator): A resource management layer that enables multiple applications to share a Hadoop cluster efficiently by managing resources and scheduling jobs.
Sqoop: A tool designed for transferring data between Hadoop and relational databases. It simplifies the process of importing data from SQL databases into HDFS and exporting it back.
Together, these tools provide a complete ecosystem that enhances Hadoop’s capabilities, making it an even more powerful tool for big data processing.
Hadoop’s Impact on Big Data
Big data is an umbrella term for data that is too large, fast, or complex for traditional data processing tools to handle. The explosion of data from sources such as social media, sensors, and online transactions has pushed the limits of conventional databases. Hadoop plays a pivotal role in the world of big data by making it possible to store and process vast amounts of data in real-time, which was previously unimaginable.
One of the main challenges in big data is not just its size but also its variety and velocity. Unlike structured data that can be neatly stored in a relational database, big data often comes in various forms, such as text, images, video, or log files. Hadoop’s flexibility in managing both structured and unstructured data is a game-changer for organizations. Whether it’s analyzing social media trends, processing sensor data from smart devices, or reviewing customer transactions, Hadoop is the backbone for handling this data.
Moreover, Hadoop’s ability to process data in parallel reduces the time required to analyze large datasets. Businesses can now extract valuable insights from their data much faster, allowing for quicker decision-making. This has led to improved business intelligence, predictive analytics, and more efficient operations in many industries, including healthcare, finance, and retail.
Conclusion
In a world where data is growing at an unstoppable pace, Hadoop stands as a vital solution for managing and processing massive datasets. Its distributed architecture, scalability, and ability to handle diverse data types make it indispensable for big data applications. By leveraging Hadoop, businesses can efficiently store, analyze, and extract valuable insights from their data. As data-driven decision-making becomes more crucial, Hadoop’s role will only expand, shaping the future of analytics, business intelligence, and large- scale data processing.