zfn9
zfn9
When it comes to audio transcription, the real challenge arises when your recordings extend beyond just a few minutes. Handling longer audio files such as interviews, podcasts, or conference talks can lead to memory issues or system crashes if not managed properly. This is where tools like Wav2Vec2 from Hugging Face’s Transformers library become incredibly useful.
While Wav2Vec2 is a powerful speech recognition model, making it work reliably with large files involves more than just uploading an audio file. This guide will show you how to effectively use automatic speech recognition (ASR) on large audio files using Wav2Vec2, covering segmentation, transcription, and post-processing techniques.
Why is Wav2Vec2 Ideal for Speech Recognition?
Wav2Vec2, developed by Facebook AI (now Meta AI), is a self-supervised model that learns audio representations from unlabeled speech data and is later fine-tuned with labeled transcripts. It is popular because it performs well with fewer labeled examples and can manage various accents and recording qualities without additional tuning.
The Hugging Face Transformers library offers a Pythonic interface to load pre-trained models, transcribe audio, and fine-tune models with your dataset. Although these models are generally optimized for shorter clips—usually under a minute—feeding longer files can result in GPU memory overloads or output truncation. This is where preprocessing, segmentation, and careful pipeline design become crucial.
Handling Long Audio Files with Segmentation
When transcribing long audio files directly using Wav2Vec2, you might encounter memory issues or incomplete outputs. Transformer-based models like Wav2Vec2 work best on shorter input sequences.
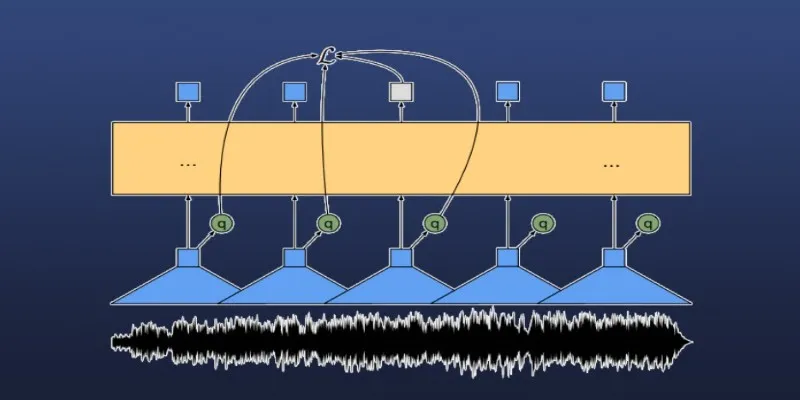
To overcome this, you need to segment the audio into manageable chunks. Python libraries like pydub, librosa, or torchaudio can split an audio file into smaller, overlapping windows. The overlapping helps avoid missing words at the boundaries. A typical approach is breaking files into 20-second windows with a 2-second overlap, balancing speed with memory efficiency and ensuring smooth transitions.
Once segmented, each chunk is processed individually through the model. However, this results in multiple short transcriptions that must be merged. Maintaining context and coherence, especially in conversational or storytelling recordings, requires post-processing logic to merge or correct these snippets.
Transcription and Tokenization
Wav2Vec2’s tokenizer works directly on raw audio (as float32 arrays). After splitting, each chunk must be converted accurately before feeding it into the model. Hugging Face provides a processor class for both feature extraction and tokenization. Using Wav2Vec2Processor, you can convert audio into the required model format.
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
import torch
import torchaudio
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
model.eval()
def transcribe(audio_chunk):
input_values = processor(audio_chunk, sampling_rate=16000, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
return processor.decode(predicted_ids[0])
This basic function can run over each chunk, with outputs stored. Ensure your audio’s sampling rate matches the model’s expectations, typically 16kHz. Use torchaudio or ffmpeg for conversions if needed.
Stitching Output and Cleaning the Transcript
After transcribing each chunk, the next step is combining them into a single document. Simple concatenation might work but often results in broken transitions. A more refined approach involves aligning overlapping segments and smoothing boundary words. While ASR models don’t return word-level timestamps by default, tools like ctc-segmentation or whisperx try to align transcriptions with timestamps.
For Wav2Vec2, unless you’ve fine-tuned a model with word alignment features, rely on basic merging logic. Discard overlapping seconds from alternate chunks, such as ending chunk 1 at 20s and starting chunk 2 at 18s, keeping only 0–20s from the first and 20–40s from the second.
Cleaning the transcript is also beneficial. Since Wav2Vec2 models don’t include punctuation by default, results are lowercase and unpunctuated. Use a punctuation restoration model—like those based on T5 or BERT—or rule-based scripts to enhance readability. Avoid introducing too many assumptions if using the transcription for subtitles or indexing.
Performance Tips and Limitations
When transcribing long files, speed can be a challenge. Since Wav2Vec2 is computationally intensive, GPU inference is preferred. If unavailable, smaller models or quantized versions like wav2vec2-base-960h offer reasonable trade-offs. Batch processing multiple chunks in parallel can help, but be cautious not to overload memory.
Remember that ASR models have limitations. They may struggle with accents, overlapping speakers, or background noise. Preprocessing steps like volume normalization, noise reduction, or silence trimming can improve accuracy. Publicly available models are typically trained on clean speech datasets, so real-world results may vary.
Fine-tuning your version of Wav2Vec2 with domain-specific audio and transcripts can yield better results. Hugging Face offers training scripts for fine-tuning with your dataset, though this requires substantial labeled data and GPU resources.
Language considerations are also crucial. While English Wav2Vec2 models perform well, support for other languages is growing but uneven. Ensure the model you use is trained in the language and dialect of your audio.
Conclusion
Making automatic speech recognition work reliably on large audio files with Wav2Vec2 requires strategic workflow design. By segmenting audio into manageable pieces, handling overlaps carefully, using a suitable processor, and cleaning up results, you can produce accurate, readable transcripts from long recordings. Wav2Vec2 is a robust choice for offline or open-source transcription, especially if you want control over the pipeline. Although setting it up for long-form audio isn’t straightforward, building the right structure around it can scale well for real-world projects.
For further information, visit the Hugging Face documentation.