zfn9
zfn9
Data without structure is chaos, especially when it’s growing rapidly. If you’re working with relational databases, keeping your data organized isn’t just helpful—it’s essential. That’s where normalization comes in. It’s one of those database concepts that everyone hears about early on, but many overlook until data anomalies start appearing or storage balloons out of control. Normalization isn’t just a rulebook—it’s a way to make your database leaner, smarter, and easier to manage over time.
If you’re wondering how to implement normalization with SQL practically, you’re in the right place. Let’s unpack what it really means and how you can actually apply it without overcomplicating things.
What is SQL Normalization and Why Does It Matter?
SQL normalization is the process of organizing a database into well-structured tables to reduce redundancy and dependency. It involves breaking large, bulky tables into smaller, more focused ones, ensuring each piece of data is stored in only one place. This structure helps maintain accuracy and consistency during operations like updates, deletions, or inserts. For example, if customer information is repeated with every order, any change to their address would need to be made in multiple rows—creating room for errors.
By separating customer and order data into distinct tables and linking them through keys, normalization simplifies data management. It also prevents anomalies like inconsistent updates or difficulty inserting data due to missing values. In short, SQL normalization makes your database more efficient, less error-prone, and easier to maintain as it grows.
The Normal Forms: A Ground-Level Explanation
Normalization follows a series of rules known as “normal forms.” These aren’t just academic checkboxes—they’re practical stages that guide you from a messy design to a more elegant structure. The most commonly applied ones are the first three:
First Normal Form (1NF):
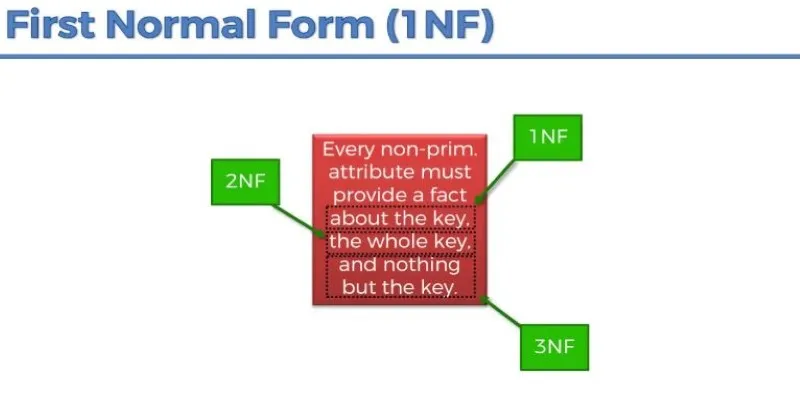
This ensures that each column contains only atomic (indivisible) values. That means no lists or sets within a column. If a table has a column like “phone_numbers” with multiple values separated by commas, it fails 1NF. You’ll need to split those values into separate rows or related tables.
Second Normal Form (2NF):
This step deals with partial dependencies—cases where non-key attributes depend on the part of a composite primary key instead of the whole key. 2NF requires your data to already be in 1NF. Suppose you’re using a table where a field depends only on a portion of the key (like a product name depending only on a product ID in a table keyed on product ID + category). In that case, it’s time to split that dependency into a new table.
Third Normal Form (3NF):
Now, you’re making sure that every non-key column is only dependent on the primary key, not on another non-key column. If you have a “department” column that determines a “manager_name,” that’s a transitive dependency. It means you should move that relationship to a new table.
Each of these forms helps refine your design, removing unnecessary repetition and focusing each table on a single, clear subject. While deeper levels exist (4NF and beyond), most real-world applications stop at 3NF unless there’s a compelling reason to go further.
How to Implement Normalization with SQL in Practice?
To understand how to implement normalization with SQL, we’ll walk through a typical example. Say you start with a single table that stores all customer orders:
VARCHAR(100), CustomerEmail VARCHAR(100), ProductName VARCHAR(100),
ProductPrice DECIMAL(10,2) ); ```
At first glance, it looks clean. However, this structure repeats customer and
product information every time someone places an order. Now, let's walk
through the normalization steps:
### Step 1: Break into Atomic Values (1NF)
Let's assume there's a list of products in one row, separated by commas.
That's a violation of 1NF. You should split each product into its rows so that
each field holds a single value.
Once your data is atomic, move on to structure.
### Step 2: Remove Partial Dependencies (2NF)
You might notice that customer data doesn’t need to be repeated with every
order. Time to separate that:
```sql CREATE TABLE Customers ( CustomerID INT PRIMARY KEY, CustomerName
VARCHAR(100), CustomerEmail VARCHAR(100) ); CREATE TABLE Orders ( OrderID INT
PRIMARY KEY, CustomerID INT, FOREIGN KEY (CustomerID) REFERENCES
Customers(CustomerID) ); ```
Now, the Orders table only stores what's necessary for the order, and the
customer info lives on its table.
### Step 3: Eliminate Transitive Dependencies (3NF)
Let’s say we were also storing ProductCategory and CategoryDescription in the
product table. But CategoryDescription depends on ProductCategory, not the
product itself. That’s transitive.
Split it again:
```sql CREATE TABLE Products ( ProductID INT PRIMARY KEY, ProductName
VARCHAR(100), ProductPrice DECIMAL(10,2), ProductCategoryID INT, FOREIGN KEY
(ProductCategoryID) REFERENCES Categories(CategoryID) ); CREATE TABLE
Categories ( CategoryID INT PRIMARY KEY, CategoryName VARCHAR(100),
CategoryDescription TEXT ); ```
That's a fully normalized design using SQL. By separating concerns into
different tables, each table now represents one idea clearly: customers,
orders, products, and categories. You can now insert, update, and delete
records with a much lower chance of error.
This structure also plays well with indexing, query optimization, and future
schema expansion. And it’s all driven by the principles of SQL normalization.
## When Not to Normalize Too Aggressively
Normalization is essential, but too much of it can backfire. Over-normalizing
leads to excessive table joins, which can slow down performance and make
queries harder to write and understand—especially for reporting tools or
business users. In high-read systems like dashboards or analytics, a bit of
denormalization can actually improve efficiency.
It's all about finding the right balance. SQL normalization shines in
transactional systems with frequent updates and inserts. However, for
reporting or data warehousing, a slightly denormalized structure may be more
practical. Understanding how to implement normalization with SQL includes
knowing when to prioritize performance over strict design rules.
## Conclusion
Normalization isn't just a best practice—it’s the backbone of reliable,
maintainable databases. By learning how to implement normalization with SQL,
you create systems that are efficient, consistent, and easier to scale.
Whether you’re designing from scratch or cleaning up a tangled schema,
applying 1NF through 3NF helps cut down redundancy and improves data
integrity. With the right structure in place, your SQL database won’t just
store data—it will support smarter queries, cleaner updates, and better
performance over time.