zfn9
zfn9
Hadoop revolutionized the handling of large datasets by introducing a distributed, cost-effective framework. Instead of relying on a single powerful machine, it allows organizations to store and process data across numerous low-cost computers. However, Hadoop’s true strength lies not just in its core but in the comprehensive range of tools that accompany it, collectively known as the Hadoop ecosystem.
Understanding the Hadoop Ecosystem
The Hadoop ecosystem is an open-source framework designed to store and process massive data using clusters of machines. At its core are three critical components:
- Hadoop Distributed File System (HDFS): Stores datasets by breaking them into smaller blocks and distributing them across nodes, ensuring fault tolerance through redundancy.
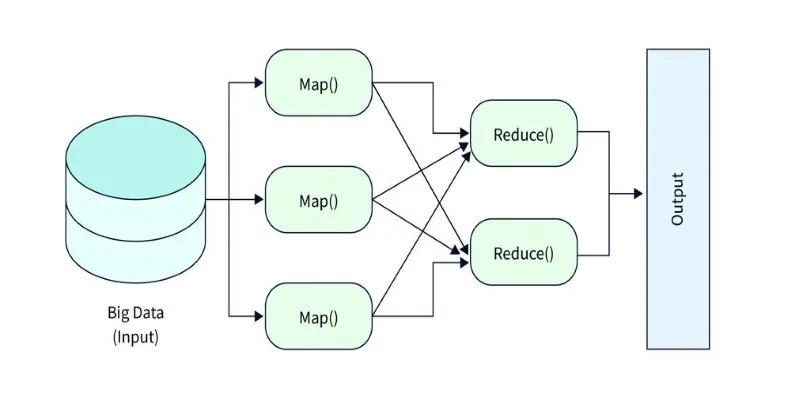
- MapReduce: Processes data by splitting computation into parallel tasks that run concurrently across many machines.
- YARN (Yet Another Resource Negotiator): Manages cluster resources, determining how jobs are distributed and executed across available hardware.
Beyond these core modules, the ecosystem offers several high-level tools to simplify tasks. For instance, Hive allows data analysts to use SQL-like queries, automatically converting them into MapReduce jobs. Pig offers a scripting-friendly way to process data, catering to those who prefer it over Java programming. HBase provides fast read and write operations for real-time access, complementing HDFS’s ability to store large, static datasets. Additional components extend Hadoop’s reach: Sqoop facilitates data movement in and out of relational databases, while Flume efficiently collects and streams event data into HDFS.
Each component is crafted to work in harmony, building on the reliability and scalability of HDFS and MapReduce. This modularity enables Hadoop to remain adaptable and relevant, even as data scales and diversifies.
How the Components Collaborate
A key strength of Hadoop lies in the seamless collaboration of its parts. When data arrives, it is stored in HDFS, broken into blocks, and distributed with redundancy. This configuration ensures that no single machine holds all the data, enhancing scalability and tolerance to hardware failures.

YARN takes charge of scheduling and managing resources, ensuring that each machine in the cluster is assigned an appropriate task without overloading any node. During processing, MapReduce organizes computation into map and reduce stages, running them in parallel across the cluster to efficiently complete jobs.
For users who find coding MapReduce jobs complex, Hive and Pig simplify the process. Hive translates SQL-like statements into MapReduce operations, while Pig scripts offer a straightforward way to define workflows. HBase caters to applications requiring quick, random access to data, rather than batch processing. For integrating external data sources, Sqoop facilitates data import and export between Hadoop and traditional databases, while Flume streams real-time logs into HDFS, enabling organizations to build comprehensive datasets.
Organizations can combine these tools in diverse ways, depending on their priorities. They can process archived data with MapReduce, analyze it interactively through Hive, or serve it in real-time with HBase — all within the same ecosystem.
Use Cases and Advantages
The Hadoop ecosystem is invaluable in industries handling large or varied data. Retail companies analyze shopping trends to personalize offers, financial institutions monitor transactions to detect fraud, healthcare providers store medical histories and support research, and governments utilize it for population statistics and urban planning.
Key Advantages:
- Scalability: Adding more machines to a cluster increases capacity and processing power without disrupting ongoing work.
- Fault Tolerance: Protects against data loss even if some machines fail.
- Cost-Effectiveness: Being open-source, it avoids high licensing costs and allows users to customize as needed.
- Flexibility: Supports structured, semi-structured, and unstructured data, offering tools like Hive for SQL-friendly users and Pig for programmers.
The ability to integrate data from various sources, process it efficiently, and serve it to end users on an affordable, distributed infrastructure has cemented Hadoop’s status as a foundation for big data projects. Despite the emergence of cloud platforms and newer technologies, many still rely on Hadoop for its reliability and flexibility.
Challenges and the Future of Hadoop
Hadoop is not without its challenges, especially for newcomers. Setting up and managing a cluster can be complex. Each component requires proper configuration, and performance tuning demands experience. While MapReduce is effective for many jobs, it can be slower than newer frameworks like Spark, which retains more data in memory for faster results.

The rise of cloud services has shifted some organizations away from managing their clusters. Cloud-based tools offer similar functionality with less operational burden, appealing to teams that prefer managed services. However, for organizations with stringent data privacy needs or those handling large volumes of sensitive data, on-premises Hadoop remains a practical choice.
The ecosystem continues to evolve, with newer components and integrations enhancing usability and supporting advanced analytics like machine learning and real-time streaming. Rather than being replaced, Hadoop serves as a backbone for modern big data solutions, often working alongside newer tools.
Conclusion
The Hadoop ecosystem provides a practical way to store, process, and analyze large datasets by combining distributed storage and computation with a rich set of supporting tools. Its core components — HDFS, MapReduce, and YARN — handle the heavy lifting, while add-ons like Hive, Pig, HBase, Sqoop, and Flume extend its capabilities. Despite challenges in setup and maintenance, its scalability, flexibility, and open-source nature make it a trusted solution across industries. As the data landscape shifts, Hadoop remains a reliable and adaptable framework for managing big data at scale.