zfn9
zfn9
Segmentation plays a crucial role in computer vision, allowing machines to effectively interpret visual data. Two major techniques, semantic segmentation and instance segmentation, help break down images but work in distinct ways. Semantic segmentation assigns each pixel to a category without distinguishing between individual objects of the same class.
Instance segmentation, on the other hand, not only classifies pixels but also separates individual objects, even if they belong to the same category. This article explores these distinctions, outlining their unique applications. By the end, you’ll have a clear grasp of how each method operates and when to apply them in computer vision tasks.
What is Semantic Segmentation?
Semantic segmentation involves classifying every pixel in an image into a predefined category, without differentiating between separate objects within the same category. For example, in an image of a street filled with cars, trees, and buildings, all vehicles would be labeled identically, all trees would have the same identifier, and the same applies to buildings—without recognizing individual objects.
This technique is especially useful when the goal is to map out general regions rather than distinct objects. Autonomous vehicles, for instance, leverage semantic segmentation to identify lanes, sidewalks, and other broad environmental elements. However, its major limitation is the inability to distinguish between multiple instances of the same class, making it unsuitable for applications requiring individual object recognition.
What is Instance Segmentation?
Instance segmentation goes a step beyond image analysis by labeling pixels into classes and distinguishing individual instances of objects within the same class. In the same street scene, instance segmentation would identify and label each car, tree, and building as an individual entity, even when they overlap or are in close proximity.

This extra layer of specificity renders it invaluable in situations where individual object separation is required. For instance, instance segmentation can distinguish among different tumors or identify different lesions within the same class in medical imaging, which is crucial for precise diagnosis. In robotics and object following, separating different entities allows for more accurate interactions with the world.
Key Differences Between Semantic and Instance Segmentation
While both semantic segmentation and instance segmentation are used to classify and understand images, the way they process and represent data differs significantly. Let’s break down the main differences between the two:
Classification vs. Detection
In semantic segmentation, the focus is on classifying pixels. This method doesn’t consider the individual objects within a category. For instance, every car in the image would be treated the same way, with no distinction between one car and another. It’s about categorization, not identification.
Instance segmentation, in contrast, goes further by recognizing and separating individual objects even if they belong to the same category. This means that while semantic segmentation might group all cars as one class, instance segmentation can label each car as a distinct entity.
Complexity
Semantic segmentation is generally simpler than instance segmentation because it only requires the algorithm to classify pixels. It doesn’t need to deal with the added complexity of separating individual objects.
On the other hand, instance segmentation involves additional steps of detecting boundaries and distinguishing between objects that might overlap or be close together. This makes instance segmentation computationally more intensive and often requires more sophisticated models, such as Mask R-CNN.
Applications
Both segmentation techniques have their applications, but they serve different purposes depending on the level of detail needed.
Semantic segmentation is often used in scenarios where general classification is sufficient. For instance, in autonomous driving, detecting the road, pedestrians, and other objects is important, but there’s less need to differentiate between individual pedestrians and cars. The focus is on understanding the environment as a whole.
In contrast, instance segmentation is used in more precise applications. For example, in medical imaging, distinguishing between individual cells or tissues is crucial for accurate diagnosis. Similarly, in retail and manufacturing, being able to identify and track individual products or parts in an assembly line can improve efficiency and accuracy.
Output Representation
The output of semantic segmentation is a segmented map where each pixel is assigned a label corresponding to the class it belongs to. However, this output doesn’t differentiate between multiple instances of the same class.
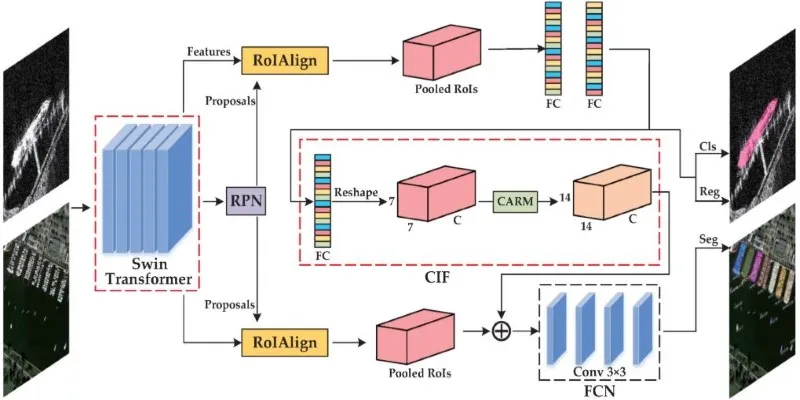
The output is more complex in instance segmentation. It provides both the segmentation map and a mask for each instance. This mask identifies the precise boundaries of each object, allowing for a more detailed understanding of the image.
How Do These Techniques Impact AI and Machine Learning?
Both semantic segmentation and instance segmentation are essential in pushing the boundaries of what machines can do with visual data. While semantic segmentation is suitable for simpler tasks that require basic object recognition, instance segmentation opens the door to more sophisticated applications that demand fine-grained understanding.
For instance, in robotics, understanding the difference between individual objects can significantly enhance object manipulation. Whether picking up groceries or assembling products, robots need to distinguish not just the category of an object (e.g., a cup) but also which specific cup to pick up.
Similarly, in the realm of autonomous driving, while semantic segmentation helps in recognizing road lanes, pedestrians, and traffic signs, instance segmentation allows the vehicle to track and avoid specific obstacles like other vehicles, cyclists, or pedestrians, improving safety.
Both techniques are fundamental to the development of more advanced AI systems, with instance segmentation being the next step in increasing machine vision’s precision.
Conclusion
Semantic segmentation categorizes pixels into classes without distinguishing individual objects, making it suitable for general recognition tasks. Instance segmentation, however, goes further by identifying and separating individual objects within the same class, enabling more precise analysis. While instance segmentation is more computationally complex, it is vital for applications requiring detailed object tracking. Understanding the differences between these techniques helps in selecting the right approach for specific AI and computer vision tasks.