zfn9
zfn9
Working with databases is not just about storing data—it’s about organizing it smartly. That’s where functional dependency in DBMS comes into play. It tells us how one piece of data relies on another, forming the backbone of well- structured tables. Without it, you risk messy duplicates, hard-to-maintain records, and unreliable queries.
Functional dependency is a simple idea with powerful effects: it decides how your tables should be built and how your data should behave. If you’ve ever wondered why certain columns belong together or how normalization works, this concept is the answer. Let’s break it down in clear, everyday terms.
What Is Functional Dependency?
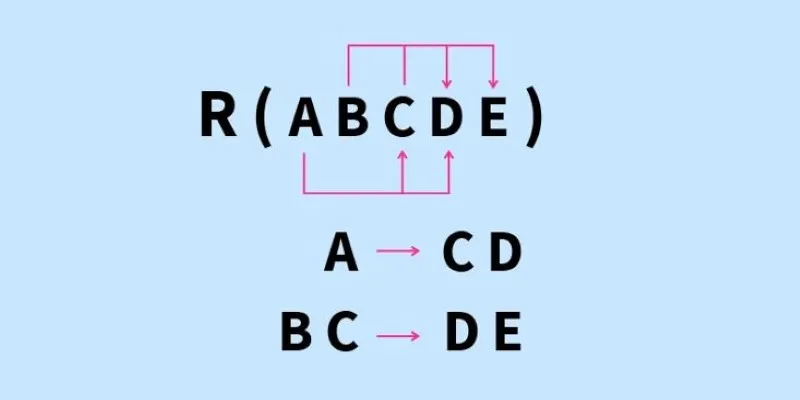
In the world of databases, functional dependency is one of those foundational ideas that quietly holds everything together. At its core, it’s about relationships between columns in a table—specifically, how the value in one column can determine the value in another. Databases define it as such: if we define A → B, we are saying that for any value of A, there is one and only one value of B. That makes A the determinant and B the dependent.
Take a simple employee table with employee_id, employee_name, and department. Since every employee_id is unique and links to just one name, we say employee_id → employee_name. You wouldn’t expect two different names for the same ID, right? That’s functional dependency in action.
This concept plays a critical role in maintaining clean and logical data. It shows us how pieces of information are tied together, making it easier to design better tables, avoid duplication, and ensure that queries return consistent, accurate results. Without it, data structures would fall into chaos.
Types of Functional Dependencies
Not all dependencies in a database are simple one-to-one relationships. Functional dependencies can vary in structure and complexity. The most common types include:
Trivial Functional Dependency
A trivial functional dependency occurs when an attribute determines itself or a subset of itself. For example, employee_name → employee_name. These dependencies are valid but don’t offer meaningful insight and usually have no impact on database design.
Non-Trivial Functional Dependency
This type occurs when the dependent attribute is not a subset of the determinant. For example, employee_id → employee_name is non-trivial since employee_name isn’t part of employee_id. These dependencies help identify unique relationships between attributes.
Fully Functional Dependency
A dependency is fully functional when removing any part of the determinant causes the dependency to break. Consider a table with course_id, student_id, and grade. If course_id and student_id together determine the grade, and neither alone can do it, then it’s a fully functional dependency: (course_id, student_id) → grade.
Partial Dependency
This occurs when an attribute depends on only part of a composite key. Using the same example as above, if course_id → grade, even though the full key is (course_id, student_id), that’s a partial dependency. Partial dependencies are often removed in the process of normalization.
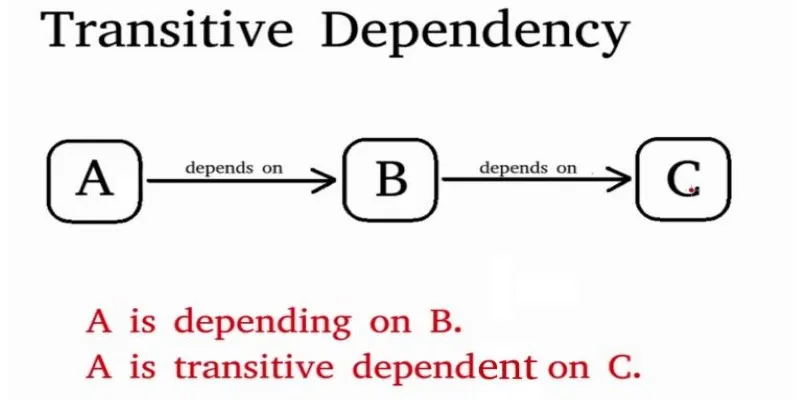
Transitive Dependency
A transitive dependency occurs when one attribute depends on another, which in turn depends on a third. If A → B and B → C, then A → C is transitive. These dependencies often cause redundancy and are removed during normalization.
Each of these types plays a role in shaping how a database is designed, maintained, and queried. Understanding the nature of each helps in diagnosing problems and improving table structure.
Importance in Database Normalization
Functional dependency in DBMS is the foundation of database normalization. Normalization is the process of organizing data to minimize duplication and increase integrity. Each stage of normalization, from the First Normal Form (1NF) to the Fifth Normal Form (5NF), uses functional dependencies to decide how tables should be split or related.
In the First Normal Form, the focus is on removing repeating groups. In the Second and Third Normal Forms, the process addresses partial and transitive dependencies. By examining how attributes depend on one another, you can break down large tables into smaller, more precise ones. This ensures that each piece of information appears only once and in the right place.
For example, imagine a table that contains student_id, student_name, course_id, and course_name. If student_id → student_name and course_id → course_name, combining all of these into one table may cause repeated names. Instead, normalization based on functional dependencies would suggest breaking this into two tables: one for students and another for courses, linked by a third enrollment table.
This structural clarity helps reduce anomalies during insert, update, or delete operations. It also improves performance by streamlining data retrieval.
Real-world Scenarios and Common Pitfalls
Let’s bring this down to a more practical level. Consider an online store’s database. If each order_id determines customer_name, shipping_address, and order_total, then all these attributes are functionally dependent on order_id. This makes sense because each order is tied to a single customer and a total amount.
Now, suppose someone stores customer_name and order_total without tying them back to order_id, thinking it’s just a small shortcut. This opens the door to errors—maybe two orders by the same customer get mixed up, or an incorrect total is stored. By clearly defining and enforcing functional dependencies, we avoid these types of mistakes.
Another common mistake is assuming functional dependency when none exists. For instance, if two people have the same last name, it doesn’t mean the last name determines anything about the person. Assuming otherwise could create false relationships in the data.
So, defining accurate dependencies isn’t just a theory—it’s a real-world tool for improving data quality and simplifying the way systems interact with information.
Conclusion
Functional dependency in DBMS is a key concept that supports the foundation of reliable and organized databases. It defines how one attribute controls another, guiding how data should be stored and structured. By understanding functional dependencies, you can design tables that avoid redundancy, reduce errors, and ensure consistency. This principle also plays a major role in normalization, making data easier to manage and retrieve. Whether you’re building a new system or refining an existing one, knowing how attributes depend on each other helps keep your database clean, efficient, and scalable for future needs. It’s a small concept with a big impact.