zfn9
zfn9
Q-Learning is a recurring topic when discussing how machines learn to make decisions. It is part of a broader category known as reinforcement learning, where an agent learns by interacting with its environment. Unlike systems dependent on complete data and fixed instructions, Q-Learning encourages exploration and learning through outcomes.
Introduction to Q-Learning
The agent tries different actions, receives feedback, and adjusts accordingly. This article breaks down how Q-Learning works, its utility, and its role in modern machine learning. This understanding is the first step toward appreciating how machines can improve through experience.
Understanding the Basics of Q-Learning
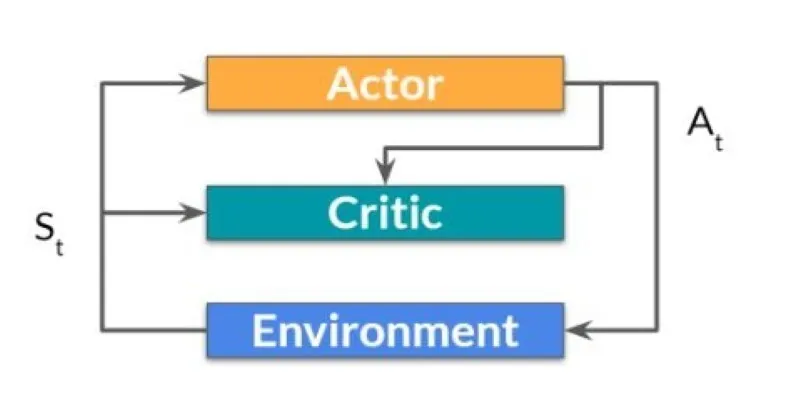
Q-Learning is a model-free reinforcement learning algorithm. Being model-free means it doesn’t need prior knowledge of the environment’s internal workings. The algorithm aims to determine the best action to take in any given state to achieve the optimal long-term outcome. It achieves this by learning the value of actions over time, storing these values in a Q-table.
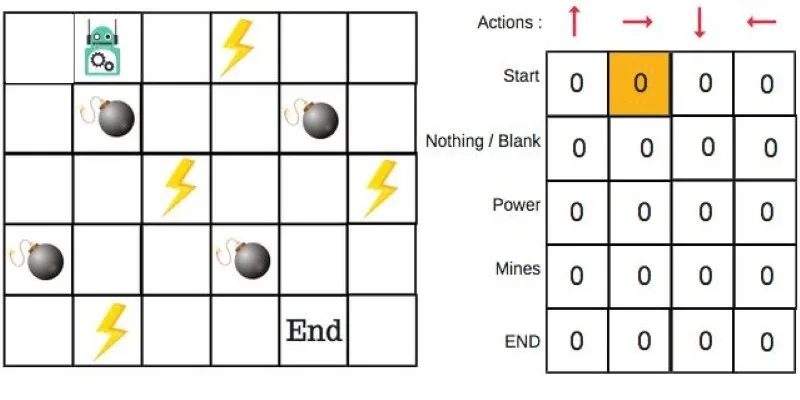
Each entry in the Q-table represents a Q-value, approximating the total expected reward of taking an action from a state and then executing optimal actions thereafter. This strategy, sometimes called a policy, relies on the idea that the table will eventually contain enough knowledge for informed decision-making.
In simple scenarios, such as a maze or grid world, a robot might use Q-values to determine moves that bring it closer to a goal without hitting walls or wasting time. The more it explores, the more accurate its Q-table becomes. Since Q-Learning doesn’t depend on a model of the world, it is apt for situations where environment modeling is difficult or impossible.
How the Q-Learning Algorithm Works
The core of Q-Learning is its update rule. After the agent takes an action, observes the result, and receives a reward, it uses a mathematical formula to update its action estimates. This process refines the strategy over time. The update rule is as follows:
Q(s, a) = Q(s, a) + α [r + γ * max(Q(s’, a’)) – Q(s, a)]
Breakdown of the Formula
- Q(s, a): Current estimate of the value for taking action in state s.
- α (alpha): Learning rate controlling the speed of knowledge updates.
- r: Reward received after the action.
- γ (gamma): Discount factor, determining the value of future rewards.
- max(Q(s’, a’)): Best predicted future reward from the next state.
This formula helps refine choices by comparing expected results with actual outcomes. If certain actions lead to better rewards, their Q-values increase, making them more likely to be chosen next time.
Imagine a game where a robot earns points for reaching a goal and loses points for hitting obstacles. Initially, its moves are random and outcomes unpredictable. But as it gains experience and updates Q-values, it recognizes which moves yield better results. Over time, it learns to make smarter choices, even starting with no prior knowledge.
Exploration vs. Exploitation and the ε-Greedy Strategy
A key challenge in Q-Learning is balancing exploration of new possibilities with exploiting actions that seem effective. If an agent always chooses the best-known action, it might miss better, untried options. Conversely, only trying new actions might prevent settling on the best strategy.

The ε-greedy strategy addresses this by having the agent pick random actions with probability ε and the best-known action with probability 1–ε. Early in training, ε is high to encourage exploration. As training progresses, ε decreases, allowing the agent to focus on learned strategies.
This strategy is simple yet effective. It prevents the agent from being stuck with suboptimal strategies and avoids overconfidence in early estimates. Tuning ε’s decrease rate affects learning quality; a fast decrease might lock in a subpar strategy, while a slow decrease could waste time on random actions. Finding the right balance is crucial in effective Q-Learning application.
Strengths, Limitations, and Applications of Q-Learning
Q-Learning excels at learning from experience without needing environment rules. It is effective in scenarios with limited states and actions and consistent feedback, such as simple games, pathfinding, and some automation tasks.
A major advantage is its simplicity. It requires minimal initial setup, building knowledge over time from action outcomes. This makes it easy to implement and test in controlled environments.
However, Q-Learning struggles in complex environments with numerous states or actions, leading to large, unmanageable Q-tables. It also assumes full visibility into the current state, which isn’t always feasible.
In these cases, techniques like Deep Q-Learning use neural networks to estimate Q-values instead of storing them in a table, handling complexity better but introducing additional challenges. Nonetheless, Q-Learning remains a strong entry point for understanding reinforcement learning principles.
Conclusion
Q-Learning enables machines to learn through experience rather than instruction. It updates action values based on outcomes, facilitating better decisions over time without needing a model of the environment. While it may falter in highly complex scenarios, its simplicity makes it ideal for grasping reinforcement learning fundamentals, particularly where clear rules and structured feedback exist.
For further understanding, consider exploring topics like Deep Q-Learning or related reinforcement learning concepts.