zfn9
zfn9
Behind AI tools that “understand” language lies one simple concept: numbers, specifically vector embeddings. These dense, multi-dimensional arrays of numbers enable machines to comprehend and compare meanings in language. If you’re involved in developing chatbots, recommendation systems, or search tools, you’ll eventually encounter vector embeddings.
However, raw embeddings alone aren’t sufficient—you need to generate, store, and make them searchable. That’s where LangChain becomes invaluable. LangChain aids in computing vector embeddings using models like OpenAI or Hugging Face and storing them in vector databases like FAISS, Chroma, or Pinecone. This guide will break down the process step by step, focusing on the core mechanics without unnecessary fluff.
Why Vector Embeddings are Crucial in LangChain?
Vector embeddings transform text into numerical vectors that convey semantic meaning. Similar sentences produce vectors that are close together in vector space, a principle that powers many AI systems—from semantic search to retrieval-based question answering.
LangChain is a framework centered around language models, excelling in how it integrates these models with embedding generation and vector storage. With LangChain, there’s no need to write boilerplate code for tokenization, encoding, or indexing. Instead, you can use its built-in tools to compute embeddings and integrate them into various vector stores.
For instance, if you’re creating a Q&A chatbot based on a document repository, the process is straightforward: split text, embed it, store it, and later retrieve relevant chunks using semantic similarity. LangChain streamlines each part of this process. You select an embedding model, input your text, and receive back vector data ready for storage and search.
Step-by-Step Guide: Computing Vector Embeddings with LangChain
LangChain simplifies embedding generation, assuming your environment is set up. First, choose an embedding model. LangChain supports several, including OpenAIEmbeddings and HuggingFaceEmbeddings. Begin by importing your preferred model and initializing it with your API key or configuration.
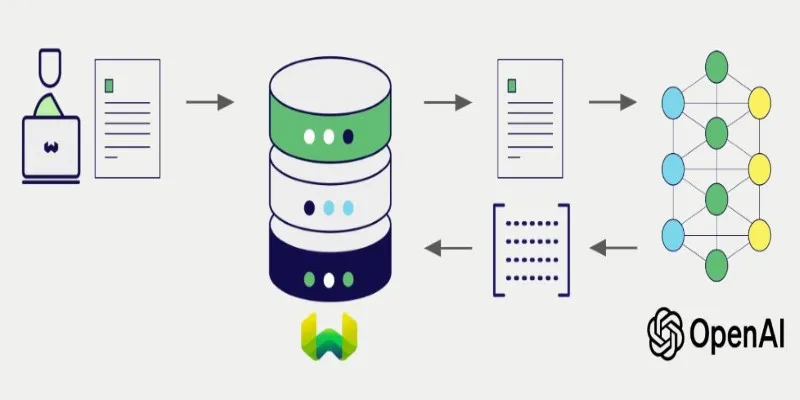
Here’s a basic example using OpenAI:
OpenAIEmbeddings() vector = embeddings.embed_query("LangChain simplifies AI
pipelines.") ```
The `embed_query` function converts text into a numerical vector—a dense array
of floating-point numbers. These vectors are typically 1536-dimensional (for
OpenAI's text-embedding-ada-002 model), allowing for the capture of subtle
semantics.
Embedding alone isn't useful unless the result is stored. That's where vector
stores like FAISS and Chroma come into play. FAISS is excellent for local
setups, while Chroma offers more indexing features out of the box.
To compute multiple embeddings from a list of texts:
```python texts = ["LangChain is great for vector search.", "Embeddings are
numeric representations.", "Vector stores are essential for retrieval."]
vectors = embeddings.embed_documents(texts) ```
You've now converted a list of sentences into a list of embeddings, ready for
storage and search. LangChain manages the backend calls to the embedding
model, eliminating the need for batching, format conversions, or tokenizer
intricacies—just supply the text and receive usable vectors. This simplicity
allows you to focus on application logic rather than machine learning
plumbing.
## Storing Vector Embeddings: Making Them Searchable and Useful
After computing embeddings, the next step is storing them. LangChain's vector
store abstraction allows you to persist these vectors along with metadata.
Whether using FAISS, Chroma, or Pinecone, the process is similar.
To store vectors using FAISS:
```python from langchain.vectorstores import FAISS from
langchain.docstore.document import Document docs =
[Document(page_content=text) for text in texts] db =
FAISS.from_documents(docs, embeddings) ```
At this point, `db` becomes your vector index. Each document is embedded and
stored with its metadata. You can perform a similarity search using:
```python query = "What is LangChain used for?" results =
db.similarity_search(query) ```
LangChain converts the query into an embedding and compares it against stored
vectors. The results include the original documents most similar to the
query—ideal for semantic search or knowledge-based agents.
To ensure persistence—meaning your vector database survives a reboot—you can
save and reload it:
```python db.save_local("faiss_index") # Later... db =
FAISS.load_local("faiss_index", embeddings) ```
This capability is crucial for production applications, enabling you to index
vectors once and reuse them across sessions or deployments. For cloud-scale
deployments, you can switch from FAISS to Pinecone or Weaviate with minimal
code changes—LangChain’s interface remains consistent.
LangChain supports metadata tagging, allowing you to attach details like
author, creation date, or topic to each Document object. This added context
helps refine searches by enabling metadata-based filters, making results more
relevant and organized for deeper, more accurate information retrieval.
## Enhancing AI Conversations with Retrieval-Augmented Generation (RAG) in
LangChain
Embedding and storing form the foundation. However, the real power emerges
when combining it with a language model using Retrieval-Augmented Generation
(RAG). This approach fetches relevant documents based on a query and uses them
to generate a grounded, context-aware answer.
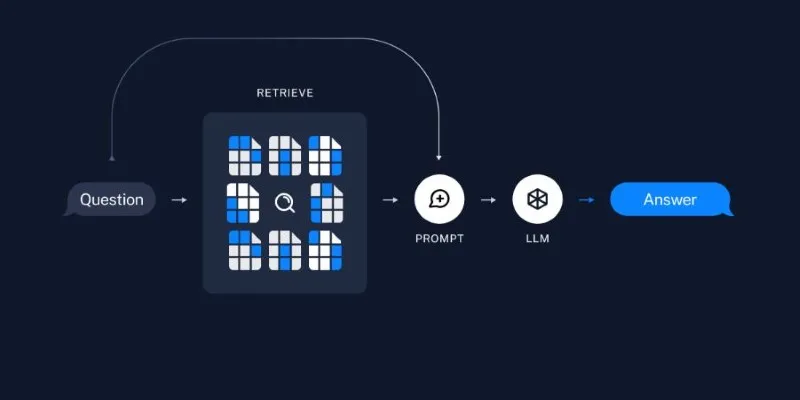
With LangChain, this is achieved with just a few lines:
```python from langchain.chains import RetrievalQA from langchain.llms import
OpenAI qa = RetrievalQA.from_chain_type(llm=OpenAI(),
retriever=db.as_retriever()) answer = qa.run("How does LangChain handle
embeddings?") ```
Here, your question is embedded, relevant documents are fetched from the
vector store, and the model uses them to generate an answer. This reduces
hallucination and produces more accurate outputs, especially useful in
knowledge-intensive domains.
LangChain manages the workflow: it computes the query embedding, finds similar
documents, merges the content into a prompt, and retrieves a response from the
model. You can extend this by adding memory, custom prompts, or chaining
additional tools, all within LangChain’s framework.
This setup—embeddings, vector store, and LLM—forms the base of many advanced
AI applications, seamlessly tied together by LangChain.
## Conclusion
Vector embeddings are vital for AI systems that effectively interpret and
retrieve language. LangChain simplifies the process of computing, storing, and
searching these embeddings through a consistent and straightforward workflow.
From generating vectors to managing them across vector stores, LangChain
streamlines complex steps into manageable parts. When paired with retrieval-
based generation, LangChain enables the creation of smarter, context-aware
applications. Whether you're developing a chatbot or a semantic search tool,
this approach facilitates advanced AI development with less hassle and greater
flexibility.