zfn9
zfn9
Designing Efficient Databases: The Role of Composite Keys in DBMS
Designing an efficient database is crucial for any data-driven application, and the key to this efficiency lies in how well your tables are structured. At the heart of this structure are keys—particularly primary keys, which ensure each record is unique. However, there are instances where a single column isn’t sufficient. This is where composite keys in a Database Management System (DBMS) come into play. A composite key combines two or more columns to uniquely identify a record, making it ideal for managing many-to-many relationships, such as tracking enrollments or order details.
In this article, we’ll explore what composite keys are, how they function, when to use them, and how they differ from regular primary keys in relational databases to maintain data integrity.
What Is a Composite Key in DBMS?
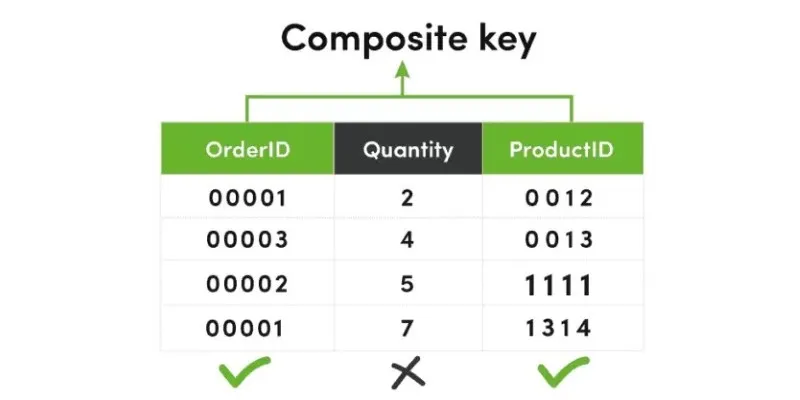
In a database, a composite key is a primary key formed by combining two or more columns. It’s used when no single column can uniquely identify a record on its own—but their combination can. Think of it as a team effort: each column contributes to the identity, and together, they ensure uniqueness.
For example, consider a table that tracks student enrollments. You might have a student_id and a course_id. Alone, neither field is unique—a student can join multiple courses, and a course can have many students. But together, the pair (student_id, course_id) forms a unique identifier for each enrollment.
Composite keys are commonly found in junction tables that connect two separate entities. Whether it’s students and classes, customers and orders, or products and warehouses, these keys hold the structure together.
The database enforces the uniqueness of this combined key to prevent duplicate entries. It ensures that a student can’t be enrolled in the same course more than once, preserving data accuracy and consistency without needing extra identifiers. Composite keys let the data speak for itself, using real-world relationships to define structure.
Why Use Composite Keys?
Composite keys are essential in situations where a natural single-column key does not exist. Instead of creating an artificial or surrogate key like an auto-incremented ID, developers may choose to use real-world data fields together to form a reliable identifier.
They are particularly useful in junction tables, which act as bridges between two main tables. Without a composite key, it becomes challenging to ensure that the records linking those two entities remain unique and accurate.
Another benefit is that composite keys can enhance data readability. When users or developers see a record identified by two or more meaningful fields—like an employee ID and project ID—it’s often easier to understand what the record represents than if an unrelated auto-generated number identified it.
Composite keys also help in enforcing referential integrity. By linking the columns in a composite key to the primary keys of two related tables, the database ensures consistency across all records and prevents orphan entries.
In short, they bring order to complexity, especially in large systems where tracking real-world relationships is essential.
Composite Key vs. Primary Key: What’s the Difference?
A composite key is essentially a type of primary key, but it uses more than one column to create a unique identifier for each row in a table. The core difference between a composite key and a traditional primary key is the number of columns involved.
A primary key typically consists of a single column, such as a user ID or a product code—something naturally unique in the data. It’s simple, easy to reference, and works well in most cases. However, when no single column can provide uniqueness on its own, a composite key becomes useful. It combines two or more columns to form a unique combination—like using both student_id and course_id to identify student enrollments.
While both key types serve the same purpose—to ensure data integrity and create relationships—composite keys often make database operations more complex. Queries using them can become longer and harder to manage. Foreign key relationships require referencing multiple columns. Indexing may also need special handling to maintain performance.
Composite keys are powerful in modeling real-world relationships, but they should be used thoughtfully. When simplicity or scalability is a concern, a single-column or surrogate primary key may be more efficient.
Real-World Applications of Composite Keys
Composite keys are not just a theoretical concept. They appear in many everyday database designs, especially in enterprise-level systems, education management platforms, inventory tracking, and more.

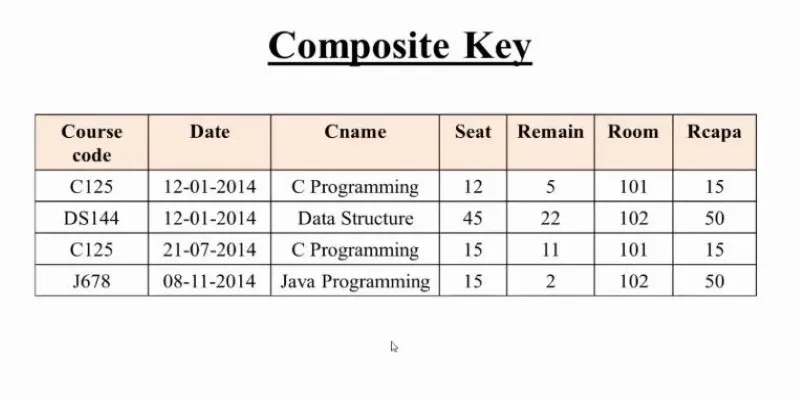
In inventory systems, a table might use warehouse_id and product_id as composite keys to track stock quantities across different storage locations. In university systems, semester_id and student_id might form a composite key to track grades or attendance per term.
E-commerce platforms may use composite keys in order tracking systems, combining order_id and product_id to identify individual items within a single order.
These examples show how composite keys are used to model real-world relationships accurately and keep the data structure clean and reliable. They reflect how multiple fields together make up the whole story, just like in real life.
However, it’s important to note that composite keys aren’t always the best choice in cases where performance is a concern or where data changes frequently; using surrogate keys (like auto-increment IDs) might make more sense. These surrogate keys can still reference the natural composite key values for data clarity.
In complex systems, it’s common to see a hybrid approach, where a surrogate key is used for internal references, and a composite key is used for unique constraints or validations.
Conclusion
Composite keys in DBMS offer a reliable solution when no single column can uniquely identify a record. By combining multiple fields, they ensure data integrity and accurately represent real-world relationships, especially in many-to-many scenarios. While they add some complexity to queries and indexing, their ability to enforce uniqueness without artificial identifiers makes them valuable in thoughtful database design. However, they should be used only when necessary. In cases where performance and simplicity are priorities, single-column primary keys or surrogate keys may be better suited. Choosing the right key type depends on the structure and goals of your database.